What is qq?
qq is a wrapper around batch scheduling systems designed to simplify job submission and management. It is inspired by NCBR’s Infinity ABS but aims to be more decentralized and easier to extend. It also supports both PBS Pro and Slurm, while making it straightforward to add compatibility with other batch systems as needed.
Although qq and Infinity ABS share the same philosophy and use very similar commands, they share no code.
Warning
qq is developed for the internal use of the Robert Vácha Lab and may not work on clusters other than those officially supported (Robox, Sokar, Metacentrum, LUMI, Karolina).
Installation
This section explains how to easily install qq on different clusters.
All installation scripts assume that you are using bash as your shell. If you use a different shell, follow this section of the manual.
Updating qq
To reinstall or update qq on a cluster, just run the installation command for the given cluster again.
Note
Updating qq is usually safe, even if you have running qq jobs on the cluster. Jobs that are already running will continue using the old version of qq. Loop jobs will automatically switch to the updated version in their next cycle.
Installing on Robox
To install qq on the Robox cluster (computers of the RoVa Lab), log in to your desktop and run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-robox-install.sh | bash
This command downloads the latest version of qq, installs it to your home directory on your desktop, and then installs it to the home directory of the computing nodes.
To finish the installation, either open a new terminal or source your .bashrc file.
Note
This does not install qq on other desktops with separate local home directories.
If you want to use qq on other desktops, you’ll need to install it there separately.
(Not installing it there however helps prevent accidentally running jobs on someone else’s desktop.)
For more details about the Robox cluster, see Robox cluster specifics.
Installing on Sokar
To install qq on the Sokar cluster (managed by NCBR), log in to sokar.ncbr.muni.cz and run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-sokar-install.sh | bash
This downloads the latest version of qq and installs it to the shared home directory of the cluster nodes.
To complete the installation, open a new terminal or source your .bashrc file.
For more details about the Sokar cluster, see Sokar cluster specifics.
Installing on Metacentrum
To install qq on Metacentrum, log in to any Metacentrum frontend and run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-metacentrum-install.sh | bash
This command downloads the latest version of qq and installs it into your home directory on brno12-cerit. The script then adds qq’s location on this storage to your PATH across all Metacentrum machines.
Because qq runs significantly slower when stored on non-local storage, the installation script also configures the .bashrc files of all Metacentrum machines to automatically copy qq from brno12-cerit to their local scratch space on login. This improves the responsiveness of qq operations.
To complete the installation, either open a new terminal or source your .bashrc file.
For more details about the Metacentrum clusters, see Metacentrum clusters specifics.
Installing on Karolina
To install qq on the Karolina supercomputer (IT4Innovations), log in to karolina.it4i.cz and run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-karolina-install.sh | bash
This downloads the latest version of qq and installs it to the shared home directory of the cluster nodes.
To complete the installation, open a new terminal or source your .bashrc file.
For more details about Karolina, see Karolina specifics.
Installing on LUMI
To install qq on the LUMI supercomputer, log in to lumi.csc.fi and run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-lumi-install.sh | bash
This downloads the latest version of qq and installs it to the shared home directory of the cluster nodes.
To complete the installation, open a new terminal or source your .bashrc file.
For more details about LUMI, see LUMI specifics.
Installing manually
Installing a pre-built version
To install a pre-built version of qq on a single computer or on several computers sharing the same home directory, run:
curl -fsSL https://github.com/VachaLab/qq/releases/latest/download/qq-install.sh | \
bash -s -- $HOME https://github.com/VachaLab/qq/releases/latest/download/qq-release.tar.gz
To finish the installation, either open a new terminal or source your .bashrc file.
Installing a pre-built version for other shells
If you’re not using bash, you’ll need to modify the qq-install.sh script.
First, download it:
curl -OL https://github.com/VachaLab/qq/releases/latest/download/qq-install.sh
Then edit this line to match your shell’s RC file:
BASHRC="${TARGET_HOME}/.bashrc"
# For example, if you use zsh:
BASHRC="${TARGET_HOME}/.zshrc"
Next, make the script executable and run it:
chmod u+x qq-install.sh
./qq-install.sh $HOME https://github.com/VachaLab/qq/releases/latest/download/qq-release.tar.gz
Building qq from source
To build and install qq yourself, you’ll need git and uv installed.
First, clone the qq repository:
git clone git@github.com:VachaLab/qq.git
Then navigate to the project directory and install the dependencies:
cd qq
uv sync --all-groups
Build the package using PyInstaller:
uv run pyinstaller qq.spec
PyInstaller will create a directory named qq inside dist. Copy that directory wherever you want and add it to your PATH.
If you want the qq cd command to work, add the following shell function to your shell’s RC file:
qq() {
if [[ "$1" == "cd" ]]; then
for arg in "$@"; do
if [[ "$arg" == "--help" || "$arg" == "-h" ]]; then
command qq "$@"
return
fi
done
target_dir="$(command qq cd "${@:2}")"
cd "$target_dir" || return
else
command qq "$@"
fi
}
If you want the autocomplete for the qq commands to work, add the following line to your shell’s RC file:
eval "$(_QQ_COMPLETE=bash_source qq)"
To finish the installation, either open a new terminal or source your .bashrc file.
Running a job
This section demonstrates how to run a basic qq job by performing a simple Gromacs simulation on the robox cluster. This assumes that you have already successfully installed qq on the cluster.
1. Preparing an input directory
Start by creating a directory for the job on a shared storage (you can also submit from a local storage on your computer but that is not recommended). This directory should contain all necessary simulation input files — in this example, an mdp, gro, cpt, ndx,top, and itp files.
2. Preparing a run script
Next, prepare a run script that creates a tpr file from the input files using gmx grompp, and then runs the simulation with gmx mdrun. We’ll configure the simulation to use 8 OpenMP threads.
A complete example of a run script:
#!/usr/bin/env -S qq run
# activate the Gromacs module
module add gromacs/2024.3-cuda
# or metamodule add gromacs/2024.3-cuda, depending on
# whether you have activated the Infinity environment or not
# prepare a TPR file
gmx_mpi grompp -f md.mdp -c eq.gro -t eq.cpt -n index.ndx -p system.top -o md.tpr
# run the simulation using 8 OpenMP threads
gmx_mpi mdrun -deffnm md -ntomp 8 -v
Important
All qq run scripts must start with the correct shebang line:
#!/usr/bin/env -S qq run
Tip
You can use the
qq shebangcommand to easily add the qq run shebang to your script.
Save this file as run_job.sh and make it executable:
chmod u+x run_job.sh
3. Submitting the job
Submit the job using qq submit:
qq submit run_job.sh -q cpu --ncpus 8 --walltime 1d
This submits run_job.sh to the cpu queue, requesting 8 CPU cores and a walltime of one day. All other parameters are determined by the queue or qq’s default settings.
Important
On Karolina and LUMI, you also have to specify the
--accountoption, providing the ID of the project you are associated with.
The batch system then schedules the job for execution. Once a suitable compute node is available, the job runs through qq run, a wrapper around bash that prepares the working directory, copies files, executes the script, and performs cleanup. You can read more about how exactly this works in this section of the manual.
4. Inspecting the job
After submission, you can inspect the job using qq info, access its working directory on the compute node with qq go, or terminate it using qq kill. For an overview of all qq commands, see this section of the manual.
5. Getting the results
Once the job finishes, the resulting Gromacs output files will be transferred from the working directory back to the original input directory. You can verify that everything completed successfully using qq info.
If your job failed (crashed) or was killed, only the qq runtime files are by default transferred to the input directory to ensure it remains in a consistent state. In these cases, the working directory on the compute node is preserved, allowing you to inspect the job files directly using qq go or to copy them back to the input directory using qq sync. On some systems, you may also want to explicitly delete the working directory afterward — to do this, use qq wipe. If you want to try running the failed/killed job again with the same parameters, respawn it using qq respawn.
Run scripts
For more complex setups — particularly for running Gromacs simulations in loops — qq provides several ready-to-use run scripts. These scripts are fully compatible with all qq-supported clusters, including Metacentrum-family clusters, Karolina, and LUMI.
Job types
qq currently supports three job types: standard, loop, continuous.
standard jobs are the default type. Any job for which you don’t specify a job-type when submitting is considered standard. Read more about standard jobs here.
loop jobs automatically submit their continuation before finishing. They also track their cycle and archive output files. Read more about them here.
continuous jobs are “poor man’s loop jobs”. Similarly to loop jobs, they automatically submit their continuation before finishing, but they do not track their cycle and do not perform any archiving operations. Read more about them here.
Standard jobs
A standard job is the default qq job type. This section describes the full lifecycle of a standard qq job.
1. Submitting the job
Submitting a qq job is done using qq submit.
qq submit submits the job to the batch system and generates a qq info file containing metadata and details about the job. This info file is named after the submitted script, has the .qqinfo extension, and is located in the input directory (often also called the submission or, somewhat confusingly, job directory).
Once submitted, the batch system takes over, finding a suitable place and time to execute your job. As a user, you don’t need to do anything else except wait for the job to run.
2. Preparing the working directory
When the batch system allocates a machine for your job, the qq run environment takes over. It first prepares a working directory for the job on the execution node.
If you requested the job to run in the input directory (by submitting with --workdir=input_dir or the equivalent --workdir=job_dir), the input directory is used directly as the working directory, and no additional setup is required.
If you requested the job to run on scratch (the default option for all environments), a working directory is created inside your allocated scratch space, and all files and directories in the input directory are copied there — except for the qq runtime files (.qqinfo and .qqout) and the “archive” directory if you are running a loop job (discussed later). During submission, you can also specify additional files you explicitly do not want to copy to the working directory.
Once the working directory is ready, qq updates the info file to mark the job state as running. Only then is your submitted script executed.
Note
In all environments supported by qq, the working directory is placed on scratch storage by default. This is typically not only faster but also safer — qq generally recommends keeping the job execution environment separate from the input directory until the job finishes successfully. This ensures that, if something goes wrong, your original input data remain untouched — no matter what your executed script did. However, all qq-supported environments also allow you to use
--workdir=input_dirif you prefer to run the job directly in the input directory.
3. Executing the script
After preparing the working directory, the submitted script is executed using bash by default. You can also specify a different interpreter, if you wish, such as Python.
The script should exit with code 0 if everything ran successfully, or a non-zero code to indicate an error. The exit code is passed back to qq, which sets the appropriate job state (finished for 0, failed for anything else).
Standard output from your script is saved to a file named after your script with the .out extension. Standard error output is stored in a similar file with the .err extension.
4. Finalizing execution
After the script finishes, qq performs cleanup.
If your job ran in the input directory, cleanup is simple: qq updates the job’s state (finished or failed) in the qq info file, and the execution ends.
If your job ran on scratch, cleanup depends on the script’s exit code.
By default, if the script finished successfully (exit code 0), all files from the working directory are copied back to the input directory, and the working directory is deleted. Finally, qq sets the job state to finished.
If the job failed (exit code other than 0), the working directory is left intact on the execution machine for inspection (you can open it using qq go, download it using qq sync, or delete it using qq wipe). Only the qq runtime files with file extensions .err and .out are copied to the input directory so you can easily check what exactly went wrong during the execution. Finally, the job state is set to failed.
Regardless of the result, qq creates an output file (named after your script with the .qqout extension) in the input directory. This file contains basic information about what qq did and when the job finished. Depending on the batch system, this file may appear either after job completion (PBS) or immediately after the job starts being executed (Slurm).
Note
The decision not to copy data from failed runs back to the input directory is a deliberate part of qq’s design philosophy. It prevents temporary or partially written files from polluting the input directory and ensures you can rerun the job cleanly after fixing the issue. In some cases, your script may even modify input files during execution and copying them back after a failure would overwrite data necessary for rerun. If you need anything from a failed run, you can copy selected files — or the entire working directory — using
qq sync.You can however change this default behavior by providing a different transfer mode when submitting the job.
Killing a qq job
If your job is killed (either manually via qq kill or automatically by the batch system, for example if it exceeds walltime), all files remain in the working directory on the execution machine and only qq runtime files are copied to the input directory. qq then stops the running script and marks the job state as killed.
Submitting the next job
After a job has completed successfully, you may want to submit a new one: for example, to proceed to the next stage of your workflow. If you try to submit another qq job from the same directory as the previous one, you will however encounter an error:
ERROR Detected qq runtime files in the submission directory. Submission aborted.
This behavior is intentional. qq enforces a one-job-per-directory policy to promote reproducibility and maintain organized workflows. Each job should reside in its own dedicated directory. (You can always override this policy by using qq clear --force but that is not recommended.)
If your previous job crashed or was terminated and you wish to rerun it, you can remove the existing qq runtime files using qq clear.
Note
Even analysis jobs that operate on results from earlier runs are recommended to be submitted from their own directories. Although qq copies only the files and directories located in the job’s input directory by default, you can explicitly include additional files or directories using the
--includeoption ofqq submit. These included items are copied to the working directory for the duration of the job, but they are not copied back after job completion. This allows you to maintain a clean one-job-per-directory workflow while still accessing any extra data your analysis requires.Example directory structure:
simulation/1_run→ directory for the simulation jobsimulation/2_analysis→ directory for the analysis job, submitted with--include ../1_run
Additional notes
- Most operations during working directory setup and cleanup are automatically retried in case of errors. This helps prevent job crashes caused by temporary storage or network issues. If an operation fails, qq waits a few minutes and retries — up to three attempts. After three failures, qq stops and reports an error. Note that qq does not retry execution of your script itself.
- If your job fails with an exit code between 90–99, this usually means a qq operation failed. Check the qq output file (
.qqout) for more details. An exit code of 99 indicates a critical or unexpected error, which usually means a bug in qq. Please report such cases.
Loop jobs
Loop jobs are jobs that automatically submit their continuation at the end of execution while tracking the current cycle and archiving output files. This section describes how they differ from standard jobs. Please read the section about standard jobs first — otherwise, this may be difficult to follow.
To turn a job into a loop job, you must set two qq submit options:
job-typetoloop, andloop-endto specify the last cycle of the loop job.
Tip
Do loop jobs seem unnecessarily complex for your use-case? Do you just want a job that submits its own continuation without worrying about archival and cycle tracking? Take a look at continuous jobs—they might be what you need.
Loop job cycles
Each loop job consists of multiple cycles. Every cycle is a separate job from the batch system’s perspective. Before a cycle finishes, it submits the next one and then ends. The next cycle continues where the previous one left off.
You can control the starting cycle using the loop-start submission option (defaults to 1). To set the final cycle, use the loop-end option. The cycle specified as loop-end will be the last one executed.
Archive directory
Each loop job creates an archive directory inside the input directory. This directory is not copied to the job’s working directory, so it can safely hold large amounts of data. In loop jobs, the archive serves two main purposes:
- to identify and initialize the current cycle of the loop job,
- to store data from previous cycles without copying them to the working directory.
You can control the archive directory’s name using the archive submission option (default: storage).
Archived files should follow a specific filename format that includes the job cycle number they belong to. You can define this format using the archive-format submission option (default: job%04d). In this format, %04d is replaced by the cycle number — for example, job0001 for cycle 1, job0002 for cycle 2, job0143 for cycle 143 and so on.
Working with the archive
You typically should not transfer files from and to the archive directly inside your submitted script. If you follow the proper naming etiquette, the qq run environment will handle all archiving operations for you.
At the start of each cycle, after copying files from the input directory to the working directory, qq run checks the archive and automatically copies all files associated with the current cycle into the working directory. For example, if the current cycle number is 8 and archive-format is job%04d, any file in the archive containing job0008 in its name will be automatically copied to the working directory. These files can then be used to initialize the next cycle of the job.
After the submitted script finishes successfully, qq moves all files matching the archive-format (for any cycle) to the archive directory. For example, if the 8th cycle produces the files job0008.txt, job0008.dat, and job0009.init, and the archive format is job%04d, all three files will be moved to the archive. Only after these files are archived are the remaining files in the working directory moved to the input directory. This ensures that archived files don’t clutter the input directory or get copied to the next cycle’s working directory.
In summary, unlike with Infinity, you do not need to explicitly fetch files from and to the archive, you just need to name them accordingly and qq will archive them automatically.
If the script fails or the job is killed, no archival is performed. As with standard jobs, all files remain in the working directory and only qq runtime files are copied to the input directory. Note that this behavior can be changed by providing a non-default archival mode.
Important
Be aware that if your input directory contains a file whose name matches the archive format, it will be copied to the storage and either just sit there uselessly or potentially overwrite something important. Make sure that files you do not want placed into the archive are named differently than the files for archival.
Resubmitting
After the current cycle finishes the execution of the submitted script, archives the relevant files, and copies the other files to the input directory, qq resubmits the job. This means that the next cycle is submitted from the original input directory. By default, the resubmission occurs from either the original input machine or the current main execution node, depending on the batch system. You can customize this behavior using the --resubmit-from option of qq submit.
The new job (the next cycle) waits for the previous one to finish completely before starting. When it begins, even before creating its working directory, qq archives runtime files from the previous cycle, renaming them according to the specified archive-format.
If the current cycle of the loop job corresponds to loop-end, no resubmission is performed.
Extending a loop job
Sometimes, after a job completes N cycles, you may realize you need M more. To extend the job, simply submit it again from the same input directory with loop-end set to N + M, either on the command line or in the submission script.
Tip
You do not need to delete any runtime files from the previous cycle — and you probably shouldn’t.
qq submitcan detect that you are extending an existing loop job and will handle the continuation correctly. This has the added benefit that the runtime files from the Nth cycle will be properly archived.
Forcing qq not to resubmit
You can manually force qq not to submit the next cycle of a loop job, even if the current cycle number has not yet reached loop-end, by returning the value of the environment variable QQ_NO_RESUBMIT from within the script:
#!/usr/bin/env -S qq run
# qq job-type loop
# qq loop-end 100
# qq archive storage
# qq archive-format md%04d
...
# if a specific condition is met, do not resubmit but finish successfully
if [ -n "${SOME_CONDITION}" ]; then
exit "${QQ_NO_RESUBMIT}"
fi
exit 0
If qq detects this exit code, it will not submit the next cycle of the loop job. The current cycle will still be marked as successfully finished (exit code 0).
Continuous jobs
Continuous jobs are jobs that automatically submit their continuation at the end of execution, but unlike loop jobs, do not track their current cycle and do not perform archiving or any other advanced operations.
They simply continue running and submitting their continuations until resubmission is explicitly stopped by returning the value of the environment variable QQ_NO_RESUBMIT from the executed script, or until the job is manually killed or fails.
To submit a continuous job, run:
qq submit (...) --job-type continuous
Caution
Using continuous jobs is not recommended for long-running simulations that generate large amounts of data.
When using local scratch as your working directory (the default), qq copies all files from the job’s input directory to the working directory. If you do not archive your generated data (such as MD trajectories), everything your simulation has generated will be copied to the working directory in each job cycle, which can consume significant time and disk space (you may easily exceed the default storage quota allocated for your working directory on scratch).
If possible, use loop jobs instead, as they support data archiving. For Gromacs simulations, qq provides run scripts for running long simulations.
Submitting and running a continuous job
When submitting a continuous job, the sequence of operations is initially the same as for a standard job. The job gets queued by the batch system, then starts, creates a working directory, copies the data from the input directory there, and executes the submitted script.
Once the script successfully finishes, the data are transferred back from the working directory to the input directory. Then the job is automatically resubmitted using the same submission options. The new job has exactly the same name as the previous job, meaning that runtime files for the next job overwrite those created for the previous job. Once the next job finishes, it also automatically submits its continuation, and this continues indefinitely until the job fails or is killed. Failed and killed jobs are not resubmitted.
Important
Continuous jobs do not perform any archiving operations and overwrite their runtime files. If you want to or need to keep runtime files for all your finished jobs, use a loop job instead.
Forcing a continuous job not to resubmit
An infinitely running job may be in some cases useful, but it is typically more useful to be able to stop a job from submitting its own continuation when some specific condition is reached.
To do this, you can use the same mechanism as for loop jobs—namely, by returning the value of the environment variable QQ_NO_RESUBMIT from within the executed script:
#!/usr/bin/env -S qq run
# qq job-type continuous
...
# if a specific condition is met, do not resubmit but finish successfully
if [ -n "${SOME_CONDITION}" ]; then
exit "${QQ_NO_RESUBMIT}"
fi
exit 0
If qq detects this exit code (${QQ_NO_RESUBMIT}), it will not submit the continuation of the continuous job. The current run will still be marked as successfully finished (exit code 0).
Extending a continuous job
In some cases, you may want to prolong a continuous job that has successfully finished (and that has been forced not to submit its own continuation). As with loop jobs, you do not need to delete the runtime files. You can simply run qq submit again—qq will recognize that a continuous job has been running in the directory and will allow submitting the job. The extended job will continue running and submitting its continuation until its script returns the environment variable QQ_NO_RESUBMIT or until the job fails or is killed.
Specifying resources
Each qq job requires some resources to run. These resources need to be requested at job submission time — the batch system uses this information to find suitable compute nodes and to ensure that jobs do not interfere with each other. Requesting too little may cause your job to fail or get killed; requesting too much may result in longer queue waiting times.
You can specify resources on the command line when running qq submit, or inside the submitted script itself using qq directives. If a resource is not specified, its value falls back to the queue default, then the server default, and finally the qq-level default for the given environment — in that order of priority.
Note
In this section of the manual, every time you see an option, something like
--nnodes,--ncpus, or--walltime, these options relate to theqq submitcommand.
Number of nodes
Use --nnodes to specify the number of compute nodes to allocate for the job.
Most jobs only need a single node, and this is typically the default. You only need to request multiple nodes if your job uses a parallelization framework that supports multi-node execution, such as MPI.
Number of CPU cores
Each compute node has a fixed number of CPU cores. You can typically request a subset of them for your job. You can specify the number of CPU cores either per node or in total:
--ncpus-per-node— specifies the number of CPU cores per requested compute node.--ncpus— specifies the total number of CPU cores for the entire job. Overrides--ncpus-per-node.
For example, if you request 2 nodes and 16 CPU cores per node, your job will have 32 CPU cores in total. You can express this either as --nnodes 2 --ncpus-per-node 16 or --nnodes 2 --ncpus 32.
Amount of memory (RAM)
Each compute node has a fixed amount of RAM. You can specify how much memory your job needs either per CPU core, per node, or in total:
--mem-per-cpu— specifies the amount of memory per requested CPU core.--mem-per-node— specifies the amount of memory per requested compute node. Overrides--mem-per-cpu.--mem— specifies the total amount of memory for the entire job. Overrides both--mem-per-cpuand--mem-per-node.
Memory sizes are specified as N<unit> where unit is one of b, kb, mb, gb, tb, pb (e.g., 500mb, 32gb).
Number of GPUs
Some compute nodes are equipped with GPUs, which can dramatically speed up certain types of computations — particularly in machine learning, molecular dynamics, and other highly parallelizable workloads. You can specify the number of GPUs either per node or in total:
--ngpus-per-node— specifies the number of GPUs per requested compute node.--ngpus— specifies the total number of GPUs for the entire job. Overrides--ngpus-per-node.
Walltime
Use --walltime to specify the maximum runtime allowed for the job.
Once this time limit is reached, the batch system kills the job regardless of whether it has finished. Examples of valid values: 1d, 12h, 10m, 24:00:00.
Working directory
A working directory is the directory where a qq job is actually executed. qq copies the data from the input directory to the working directory, executes the submitted script there, and then copies the data back.
Typically, the working directory resides on a compute node’s local storage, but it can also be on a shared filesystem — or even be the same as the input directory.
How the working directory is created depends on the batch system and the specific environment.
Robox, Sokar, and Metacentrum clusters
On Robox, Sokar, and all Metacentrum clusters (collectively known as “clusters of the Metacentrum family”), the working directory is, by default, created on the local scratch storage of the main compute node assigned to the job. You can, however, explicitly choose to use SSD scratch, shared scratch, in-memory scratch (if available), or even use the input directory itself as the working directory.
To control where the working directory is created, use the work-dir option (or the equivalent spelling workdir) of the qq submit command:
--work-dir scratch_local– Default option on Metacentrum-family clusters. Creates the working directory on an appropriate local scratch storage. Depending on the setup, it may also be created on SSD scratch.--work-dir scratch_ssd– Creates the working directory on SSD-based scratch storage.--work-dir scratch_shared– Creates the working directory on shared scratch storage accessible by multiple nodes.--work-dir scratch_shm– Creates the working directory in RAM (in-memory scratch). Useful for jobs requiring extremely fast I/O. Note that if your job fails, your data are immediately lost.--work-dir input_dir– Uses the input directory itself as the working directory. Files are not copied anywhere. Can be slower for I/O-heavy jobs.--work-dir job_dir– Same asinput_dir.
Tip
Not all scratch types are available on every compute node. Use
qq nodesto see which storage options are supported by each node.
For more details on scratch storage types available on Metacentrum-family clusters, visit the official documentation.
Specifying the working directory size
Local, SSD, and shared scratch
By default, qq allocates 1 GB of storage per CPU core when using a scratch directory. If you need a different amount of storage, you can adjust it using the following qq submit options:
--work-size-per-cpu(or--worksize-per-cpu) — specifies the amount of storage per requested CPU core.--work-size-per-node(or--worksize-per-node) — specifies the amount of storage per requested compute node.--work-size(or--worksize) — specifies the total amount of storage for the entire job.
Note
--work-size-per-nodeoverrides--work-size-per-cpu.--work-sizeoverrides both--work-size-per-cpuand--work-size-per-node.
Example:
qq submit --work-size 16gb (...)
# or
qq submit --work-size-per-cpu 2gb (...)
Note
Storage sizes are specified as
N<unit>where unit is one ofb,kb,mb,gb,tb,pb(e.g.,500mb,32gb).
In-memory scratch
If you use --work-dir scratch_shm, you should allocate memory instead of work-size, using the mem, mem-per-node, or mem-per-cpu options. Make sure the total allocated memory covers both your program’s memory usage and your in-memory storage needs. By default, qq allocates 1 GB of RAM per CPU core for all jobs.
Note
--mem-per-nodeoverrides--mem-per-cpu.--memoverrides both--mem-per-cpuand--mem-per-node.
Example:
qq submit --mem 32gb (...)
# or
qq submit --mem-per-cpu 4gb (...)
Not requesting scratch
If you use --work-dir input_dir (or --work-dir job_dir), the available storage is limited by your shared filesystem quota.
Karolina supercomputer
On the Karolina supercomputer, the working directory is, by default, created inside your project directory on the shared scratch storage. You can, however, also choose to use the input directory itself as the working directory.
To control where the working directory is created, use the work-dir option (or the equivalent spelling workdir) of the qq submit command:
--work-dir scratch– Default option on Karolina. Creates the working directory on the shared scratch storage.--work-dir input_dir– Uses the input directory itself as the working directory. Files are not copied anywhere. If you use this option, it is strongly recommended to submit from the scratch storage.--work-dir job_dir– Same asinput_dir.
Tip
Recommendation:
- Submit jobs from your Project storage (
/mnt/...). With the default--work-diroption, qq automatically copies your data to scratch, executes the job there, and then copies the results back to your input directory.- The size of the working directory on Karolina is limited by your filesystem quota, so you do not need to specify the
work-sizeoption.
LUMI supercomputer
On the LUMI supercomputer, the working directory is, by default, created inside your project directory on the shared scratch storage. You can, however, also choose to create the working directory on the flash storage or use the input directory itself as the working directory.
To control where the working directory is created, use the work-dir option (or the equivalent spelling workdir) of the qq submit command:
--work-dir scratch– Default option on LUMI (purely for consistency with the behavior of qq in other environments). Creates the working directory on the shared scratch storage.--work-dir flash– Creates the working directory on the shared flash storage. This storage can be faster for I/O-heavy jobs. Note that on LUMI, you are billed for the amount of storage you use and flash storage is much more expensive than scratch storage!--work-dir input_dir– Recommended option. Uses the input directory itself as the working directory. Files are not copied anywhere. If you use this option, you should submit the job from the scratch or flash storage.--work-dir job_dir– Same asinput_dir.
Tip
Recommendations:
- Submit jobs from your project’s scratch (
/scratch/<project_id>) and using the option--workdir input_dir!- On LUMI, you are billed for the amount of storage you use! Try to avoid storing large amounts of data in the project’s storages.
For more details on storage types available on LUMI, visit the official documentation.
Node properties
Some clusters have compute nodes with special hardware or software configurations, identified by node properties. Use --props to specify which properties are required or prohibited for your job. The value is a colon-, comma-, or space-separated list of property expressions.
A property can be a simple boolean flag (a node either has it or it doesn’t), or it can carry a specific value, in which case it is expressed as property=value. To prohibit a property or a property value, prefix it with ^. For example:
--props cl_two— the job will only run on nodes that have thecl_twoproperty.--props ^cl_two— the job will only run on nodes that do not have thecl_twoproperty.--props cl_two,singularity— the job will only run on nodes that have both thecl_twoandsingularityproperties.--props gpu_cap=sm_120— the job will only run on nodes equipped with GPUs with compute capability 12.0 (Blackwell).--props gpu_cap=^sm_120— the job will not run on nodes equipped with GPUs with compute capability 12.0 (Blackwell).
You can use qq nodes to browse the available nodes and their properties.
Important
Prohibiting property values is only supported for the PBS batch system (on Robox, Sokar, Metacentrum).
vnode property
On Robox, Sokar, and Metacentrum, each compute node has a special vnode property identifying that specific node. The value of the vnode attribute corresponds to the name of the node. You can use this attribute to force your job to run on a particular node (--props vnode=zeroc1) or to prevent it from running there (--props vnode=^zeroc1).
Cluster specifics and recommendations
In this section, we describe behavior that is specific to the individual qq-supported clusters and provide recommendations on how to submit and manage jobs on these clusters.
Robox, Sokar, and Metacentrum clusters
-
Use shared storages (e.g.,
brno14-ceitec,brno12-cerit) for storing your simulation data and submitting jobs. -
With default options, qq automatically allocates storage on the compute node(s), executes your job there, and transfers the data back. qq takes care of these copying operations.
-
If you want to know more about configuring the storage qq uses for your job, read this section of the manual.
-
When writing scripts to be executed, you can assume that all files in the script’s parent directory will be accessible using relative paths. You can also use absolute paths to access files on shared storages. However, you cannot easily access the local storage on your desktop.
-
From your Robox desktop, you can submit jobs to all Metacentrum-family clusters (see Inter-cluster job management).
-
Metacentrum-family clusters are very heterogeneous — you can use pretty much any number of CPUs and GPUs you need, as long as they fit on a single node. Running multi-node jobs can be complicated, as most clusters do not have fast interconnections between individual compute nodes.
-
On Metacentrum, some nodes or node groups may be slow or unstable. You can filter them out by submitting with
--props ^cl_<cluster_name>to exclude a cluster, or with--props vnode=^<node_name>to exclude a specific node. -
On Robox, you should generally not submit to the
desktopsqueue as it only contains desktops (duh). By default, qq is not installed on other people’s desktops, so your jobs will most likely crash. Instead, use thecpuorgpuqueues. If you want to submit to your own desktop, you can use thedesktopsqueue but must explicitly select your desktop (using--props vnode=YOUR_DESKTOP_NAME).
Tip
Click here for detailed external documentation of the Metacentrum family clusters.
Karolina supercomputer
-
Karolina has three different storages:
- Home storage: small capacity
- Project storage: large capacity, slow, persistent
- Scratch storage: large capacity, fast, regularly cleared
-
All storages are shared across all nodes of the supercomputer.
-
It is recommended to store simulation data in the Project storage and submit jobs from there. Data on the Project storage are not deleted until the project finishes, and this storage has a large capacity (unlike Home storage).
-
Prefer to not submit jobs from the Scratch storage, as its content is regularly deleted and you can lose your data.
-
With default options, when submitting from the Project storage, qq automatically creates a directory on Scratch storage, executes your job there, and transfers the data back. qq takes care of these copying operations.
-
If you want to know more about configuring the storage qq uses for your job, read this section of the manual.
-
Submit jobs with the
--accountoption providing your project ID. You can find your project ID by runningit4ifree(left-most column, in the formatOPEN-12-34). -
When submitting CPU-only jobs (queues starting with
qcpu), you always need to allocate a full compute node. Each CPU node has 128 CPU cores. If you do not specify the number of CPUs, qq will use the correct value automatically. -
For most Gromacs simulations, it is recommended to simulate multiple systems as part of a single node-wide job. You can use the
qq_loop_reor theqq_flex_rerun scripts for that. -
When submitting CPU+GPU jobs (queues starting with
qgpu), you can allocate as little as 1/8 of a compute node, which corresponds to 1 GPU and 16 CPU cores. -
Karolina’s compute nodes have fast interconnections, making it easy to efficiently run jobs across multiple nodes.
Tip
Click here for detailed external documentation of the Karolina supercomputer.
LUMI supercomputer
-
LUMI has four different storages:
- User home (
/users/<username>) — small capacity - Project space (
/project/<project_id>) — small capacity, slow - Project scratch (
/scratch/<project_id>) — large capacity, fast - Project flash (
/flash/<project_id>) — medium capacity, super fast
- User home (
-
All storages are shared across all nodes of the supercomputer.
-
All storages are persistent for the duration of the project, i.e., data are not deleted from any of them until the project completes. However, you are billed for using the storages, so try to keep the amount of stored data low.
-
It is recommended to store simulation data on the scratch space and submit jobs from there. When doing so, submit with the
--workdir input_diroption so that your data are not needlessly copied around. -
If you want to know more about configuring the storage qq uses for your job, read this section of the manual.
-
Submit jobs with the
--accountoption providing your project ID. You can find your project ID by runninglumi-allocations(project ID should look like this:project_123456). -
When submitting to the
standard-g(CPU+GPU) orstandard(CPU-only) queues, you need to allocate full nodes. On each node, you can request 56 (standard-g) or 128 (standard) CPU cores. -
For most Gromacs simulations, it is recommended to simulate multiple systems as part of a single node-wide job. You can use the
qq_loop_reor theqq_flex_rerun scripts for that. -
When submitting to the
small-g(CPU+GPU) orsmall(CPU-only) queues, you can allocate a smaller amount of resources. -
The strongly recommended ratio of GPUs to CPU cores on all GPU queues is 1:7 (see here for more details).
-
Each LUMI CPU core can run two threads. This means that when you request N CPU cores (e.g., 7),
qq jobswill report your job as using 2N cores (e.g., 14) once it starts running. This is expected behavior. -
When running Gromacs, you can choose between using N or 2N OpenMP threads per node. Depending on your setup, one may perform better than the other. By default, qq run scripts for Gromacs use N OpenMP threads. To use 2N threads instead, replace the following lines in the scripts
export OMP_NUM_THREADS="${NTOMP}" (...) ${PLUMED} -ntomp ${NTOMP} ${APPEND} -nb ${NB} -pin on -maxh ${MAX_TIME}with
export OMP_NUM_THREADS="$((NTOMP * 2))" (...) ${PLUMED} -ntomp $((NTOMP * 2)) ${APPEND} -nb ${NB} -pin on -maxh ${MAX_TIME} -
LUMI’s compute nodes have fast interconnections, making it easy to efficiently run jobs across multiple nodes.
Tip
Click here for detailed external documentation of the LUMI supercomputer.
Commands
qq provides a range of commands for submitting, executing, monitoring, and managing your jobs, as well as for displaying information about available compute nodes and submission queues. This section describes how to use each of them.
Each command is run in the terminal using the following syntax:qq [COMMAND] [ARGS] [OPTIONS]
For example:qq info 123456 -b
prints a brief summary of the job with ID 123456.
To see a list of all available qq commands, simply type:qq
For detailed information about a specific command, use:qq [COMMAND] --help
qq cd
The qq cd command is used to navigate to the input directory of a job. It is qq’s equivalent of Infinity’s pgo when used with a job ID.
Quick comparison with pgo
- Unlike
pgo,qq cddoes not have a dual function.
pgocan either open a new shell on the job’s main node or navigate to the job’s input directory depending on the arguments provided.qq cd, on the other hand, always navigates to the input directory of the specified job in the current shell. It never opens a new shell.- If you want to open a shell in the job’s working directory instead, use
qq go.
Description
Changes the current working directory to the input directory of the specified job.
qq cd [OPTIONS] JOB_ID
JOB_ID — Identifier of the job whose input directory should be entered.
Examples
qq cd 123456
Changes the current shell’s working directory to the input directory of the job with ID 123456 located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the server address.
Notes
- Works with any job type, including those not submitted using
qq submit.
qq clear
The qq clear command is used to remove qq runtime files from the current or specified directory or directories. It is qq’s equivalent of Infinity’s premovertf.
Quick comparison with premovertf
qq clearchecks whether the qq runtime files belong to an active or successfully completed qq job.
- If they do, the files are not deleted (if you really want to delete them, you have to use the
--forceflag).- If they do not, the files are deleted without asking for confirmation.
- In contrast,
premovertfsimply lists the files and always asks for confirmation before deleting them (unless run aspremovertf -f).qq clearcan operate on a specific directory or even multiple directories at once using the-d/--diroption.
Description
Deletes qq runtime files from the current directory or specified directories.
qq clear [OPTIONS]
Options
-
-d,--dir— One or more directories from which to clear qq runtime files. Supports globs. -
--force— Force deletion of all qq runtime files, even if they belong to active or successfully completed jobs.
Examples
qq clear
Deletes all qq runtime files (files with extensions .out, .err, .qqinfo, .qqout) from the current directory, provided these files are not associated with any job or belong to a job that has been killed or has failed. If multiple jobs are represented in the directory, only files related to killed or failed jobs are deleted. This helps prevent accidental removal of files from running or successfully finished jobs.
qq clear -d gromacs/popc/job1
Deletes all suitable qq runtime files from directory corresponding to the relative path gromacs/popc/job1.
qq clear -d gromacs/popc/job*
Deletes all suitable qq runtime files from directories corresponding to paths matching the glob pattern gromacs/popc/job* (e.g., gromacs/popc/job1, gromacs/popc/job2, gromacs/popc/job3).
qq clear --force
Deletes all qq runtime files from the current directory, regardless of their job state. In other words, all files with extensions .out, .err, .qqinfo, and .qqout will be removed. This is dangerous — only use the --force flag if you are absolutely sure you know what you are doing!
Notes
- You should not delete the
.qqinfofile of a running job, as this will cause the job to fail! If you use justqq clearwithout--force, you don’t need to worry about accidentally deleting it, sinceqqwill only delete files that are safe to be deleted.
qq go
The qq go command is used to navigate to the working directory of a job. It is qq’s equivalent of Infinity’s pgo when used in an input directory.
Quick comparison with pgo
- Unlike
pgo,qq godoes not have a dual function.
pgocan either open a new shell on the job’s main node or navigate to the job’s input directory depending on the arguments provided.qq go, on the other hand, always opens a new shell in the job’s working directory (on the job’s main node, if available).- If you want to navigate to the input directory instead, use
qq cd.- If you use
qq gowith a job ID, a new shell in the job’s working directory will be opened.qq goalways attempts to access the job’s working directory if it exists, even if the job has failed or been killed — no--forceoption is required.
Description
Opens a new shell in the working directory of the specified qq job, or in the working directories of qq jobs found in the specified directories.
qq go [OPTIONS] JOB_ID...
JOB_ID… — One or more IDs of jobs whose working directories should be entered. Optional.
If no JOB_ID and no directory are specified, qq go searches for qq jobs in the current directory. If multiple suitable jobs are provided or found, qq go opens a shell for each job in turn.
Options
-
-d,--dir— One or more directories to search for qq jobs in. Supports globs. -
-a,--all— Open a shell in the working directories of all your unfinished jobs. -
-s,--server— Operate on jobs on the specified batch server. If not specified, the current server is used. Only used with--all.
Examples
qq go 123456
Opens a new shell in the working directory of the job with ID 123456 on its main working node. If you use just the numerical portion of the job ID, the job is assumed to be located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the server address.
If the job does not exist, is not a qq job, its info file is missing, or the working directory no longer exists, the command exits with an error. If the job is not yet running, the command waits until the working directory is ready.
qq go 123456 144844 156432
For each of the specified jobs (123456, 144844, 156432), qq go opens a new shell in its working directory.
qq go
Opens a new shell in the working directory of the job whose info file is present in the current directory. If multiple suitable jobs are found, qq go opens a shell for each job in turn.
qq go -d /path/to/dir
Opens a new shell in the working directory of the job whose info file is present in directory /path/to/dir. If multiple suitable jobs are found, qq go opens a shell for each job in turn.
qq go -d /path/to/job*
Opens a new shell in the working directories of all jobs located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3).
qq go --all
Opens a new shell in the working directories of all your uncompleted (i.e, running and queued) qq jobs in turn.
qq go --all --server meta
Opens a new shell in the working directories of all your uncompleted qq jobs associated with the Metacentrum batch server.
Notes
- Uses
cdfor local directories orsshfor remote hosts. - Does not change the working directory of the current shell; it always opens a new shell at the destination.
qq info
The qq info command is used to monitor a qq job’s state and display information about it. It is qq’s equivalent of Infinity’s pinfo.
Quick comparison with pinfo
- You can use
qq infowith a job ID to obtain information about a qq job without having to navigate to its input directory. You can even provide IDs of multiple jobs.- You can provide
qq infowith one or more directories to search for qq jobs in. Information are then displayed for all collected qq jobs.- Unlike
pinfo,qq infofocuses only on the most important details about a job.
The output is intentionally compact and easier to read.
Description
Displays information about the state and properties of the specified qq jobs or of qq jobs found in the specified directories.
qq info [OPTIONS] JOB_ID...
JOB_ID… — One or more IDs of jobs to display information for. Optional.
If no JOB_ID and no directory are provided, qq info searches for qq jobs in the current directory. If multiple jobs are provided or found, qq info prints information for each job in turn.
Options
-
-d,--dir— One or more directories to search for qq jobs in. Supports globs. -
-a,--all— Print info for all your unfinished jobs. -
-s,--server— Collect jobs from the specified batch server. If not specified, the current server is used. Only used with--all. -
-b,--brief,--short— Display a brief summary of the job.
Examples
qq info 740173
Displays the full information panel for the job with ID 740173 located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the server address.
This command only works if the job is a qq job with a valid and accessible info file, and the target batch server is reachable from the current machine.
This is what the output might look like:
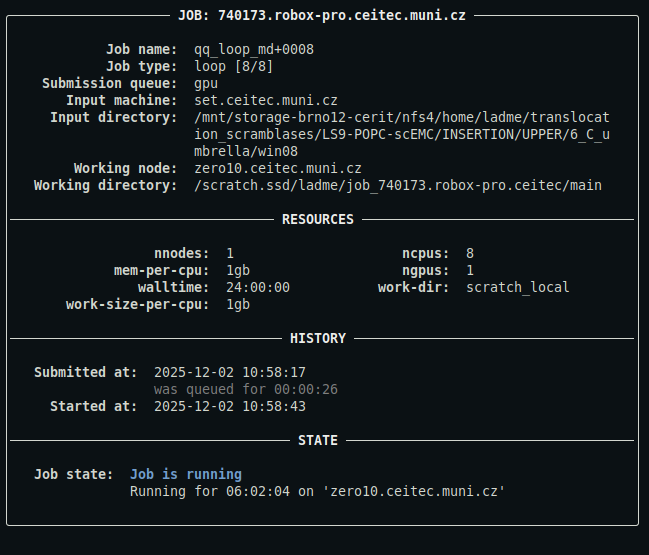
For a detailed description of the output, see below.
qq info 740173 741234 741236
Displays full information panels for jobs 740173, 741234, and 741236.
qq info
Displays full information panel for all jobs whose info files are present in the current directory.
This is what the output might look like:
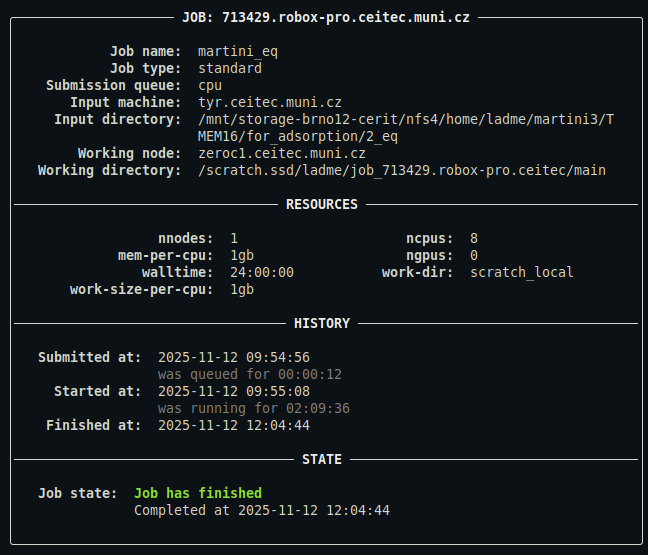
For a detailed description of the output, see below.
qq info -b
Displays brief information for all jobs whose info files are present in the current directory.
qq info -d /path/to/dir
Displays full information panels for all jobs whose info files are present in directory /path/to/dir.
qq info -d /path/to/job* -b
Displays brief information for all jobs located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3). Useful for monitoring job collections.
qq info --all
Displays full information panels for all your uncompleted (i.e, running and queued) qq jobs.
qq info --all --server meta
Displays full information panels for all your uncompleted qq jobs associated with the Metacentrum batch server.
Description of the output
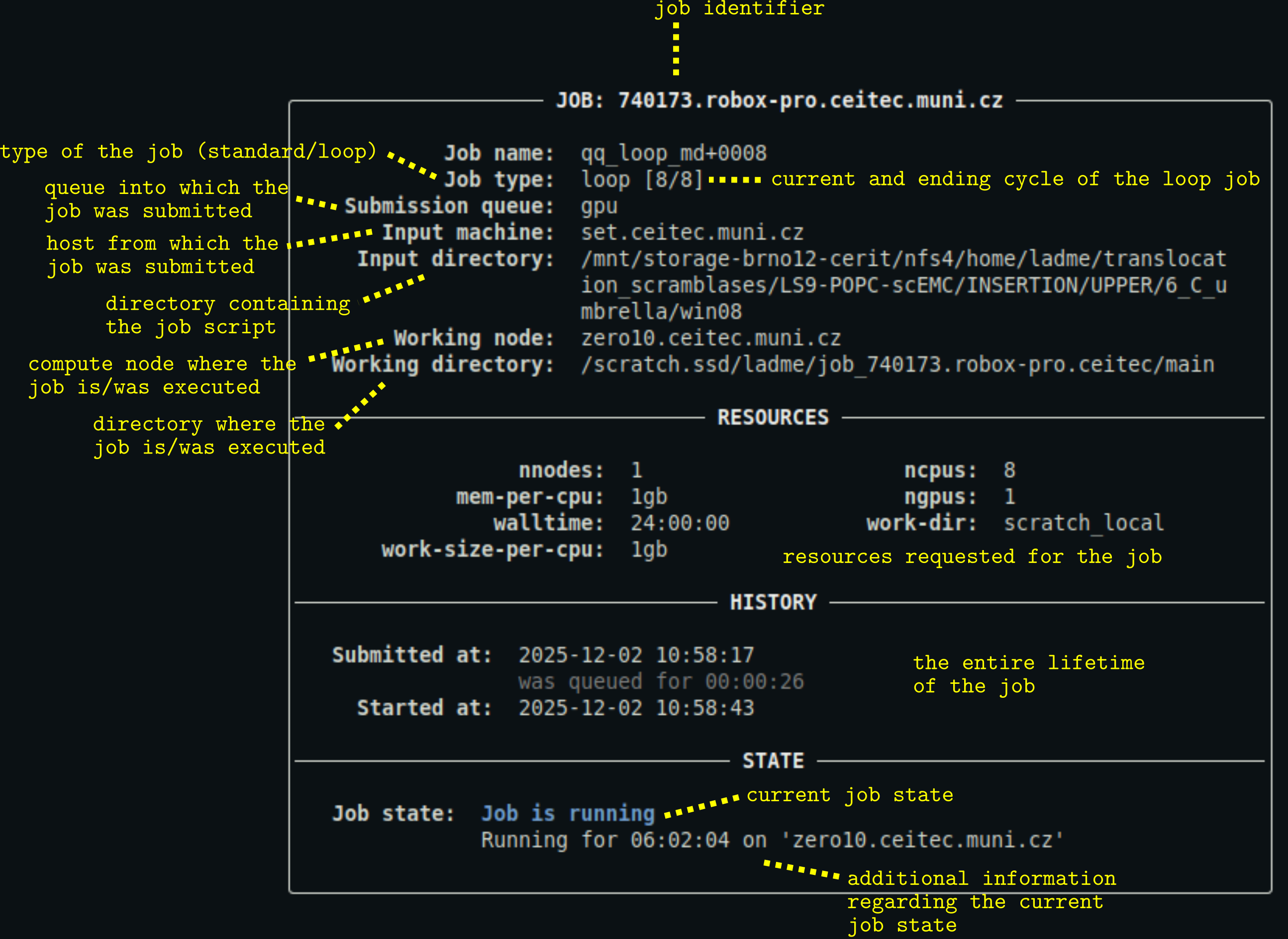
- You can customize the appearance of the output using a configuration file.
qq jobs
The qq jobs command is used to display information about a user’s jobs. It is qq’s equivalent of Infinity’s pjobs.
Quick comparison with pjobs
- Unlike
pjobs,qq jobsalways shows the nodes that the job is running on, if any are assigned.- Unlike
pjobs,qq jobsdistinguishes between failed/killed and successfully finished jobs in its output.
Description
Displays a summary of your jobs or the jobs of a specified user. By default, only unfinished jobs are shown.
qq jobs [OPTIONS]
Options
-
-u,--userTEXT— Username whose jobs should be displayed. Defaults to your own username. -
-e,--extra— Include extra information about the jobs. -
-a,--all— Include both uncompleted and completed jobs in the summary. -
-sTEXT,--serverTEXT— Show jobs for a specific batch server. If not specified, jobs on the default batch server are shown. -
--yaml— Output job metadata in YAML format.
Examples
qq jobs
Displays a summary of your uncompleted jobs (queued, running, or exiting). This includes both qq jobs and any other jobs associated with the default batch server.
This is what the output might look like:
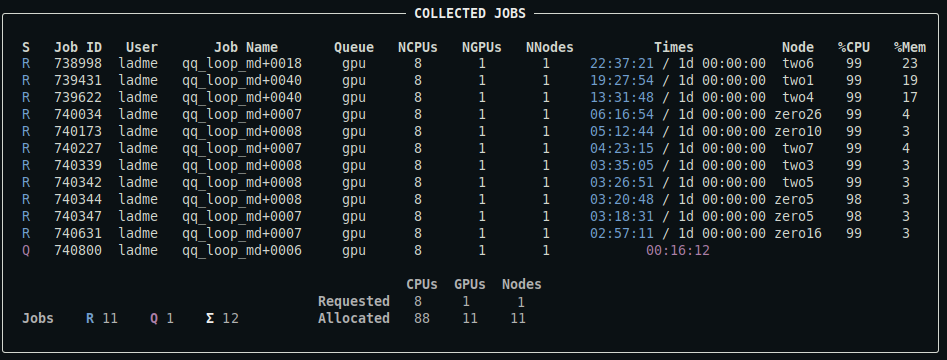
For a detailed description of the output, see below.
qq jobs -u user2
Displays a summary of user2’s uncompleted jobs.
qq jobs -e
Includes extra information about your jobs in the output: the input machine (if available), the input directory, and the job comment (if available).
qq jobs --all
Displays a summary of all your jobs associated with the default batch server, both uncompleted and completed. Note that the batch system eventually removes records of completed jobs, so they may disappear from the output over time. This is what the output might look like:
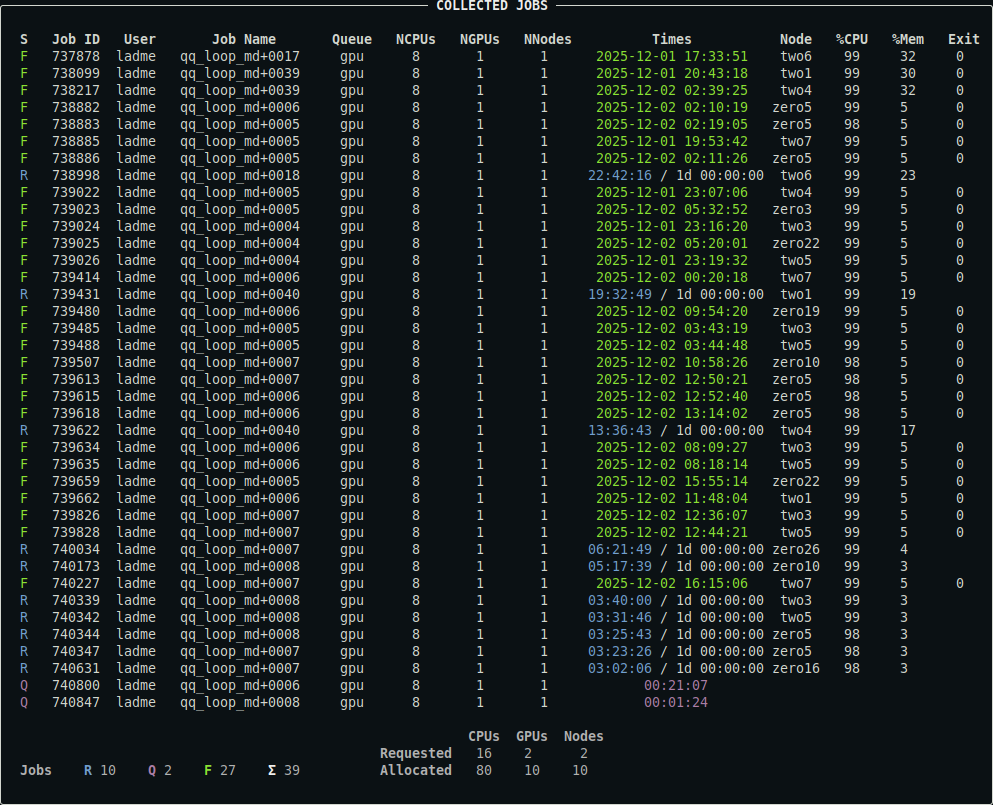
For a detailed description of the output, see below.
qq jobs --server sokar
Displays a summary of all your uncompleted jobs associated with the sokar batch server that are available to you. sokar is a known shortcut for the full batch server name sokar-pbs.ncbr.muni.cz. You can use either of them. For more information about accessing information from other clusters, read this section of the manual.
qq jobs --yaml
Prints a summary of your uncompleted jobs in YAML format. This output contains all available metadata as provided by the batch system.
Notes
- This command lists all types of jobs, including those submitted using
qq submitand jobs created through other tools. - The run times and job states may not exactly match the output of
qq info, sinceqq jobsrelies solely on batch system data and does not use qq info files.
Description of the output
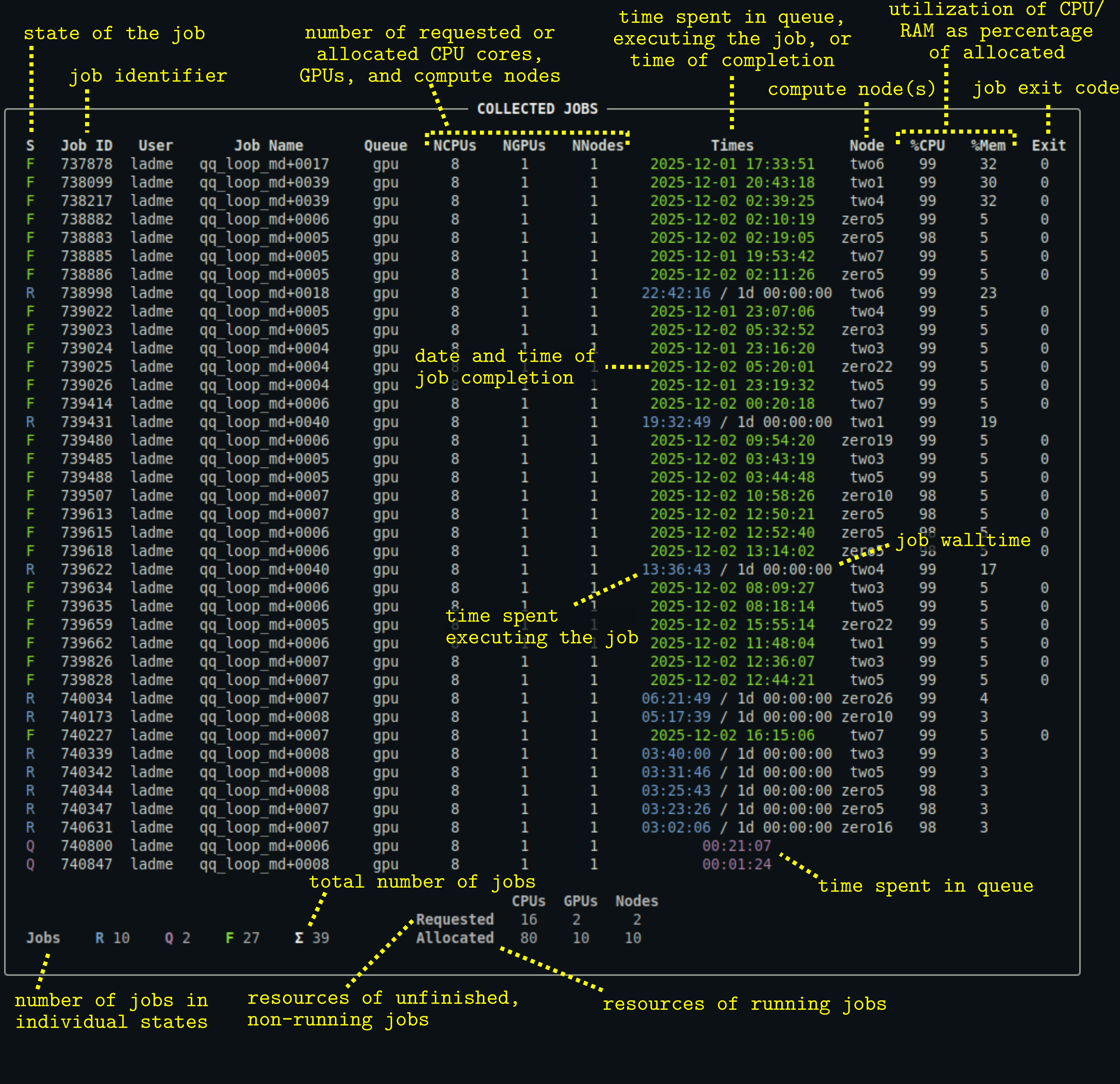
- The output of
qq statis the same, except that it displays the jobs of all users. - You can control which columns are displayed and customize the appearance of the output using a configuration file.
- Note that the
%CPUand%Memcolumns are not available on systems using Slurm (Karolina, LUMI).
qq kill
The qq kill command is used to terminate qq jobs. It is qq’s equivalent of Infinity’s pkill.
Quick comparison with pkill
- You can use
qq killwith a job ID to terminate a job without having to navigate to its input directory. You can even provide multiple IDs to kill multiple jobs at once.- You can provide
qq killwith one or more directories to search for qq jobs in. All discovered jobs are then killed.- When prompted to confirm that you want to terminate a job,
qq killonly requires pressing a single key (yto confirm or any other key to cancel), instead of typing ‘yes’ and pressing Enter.qq kill --forcewill attempt to terminate jobs even if qq considers them finished, failed, or already killed. This is useful for removing stuck or lingering jobs from the batch system.
Description
Terminates the specified qq jobs or all qq jobs in the specified directories.
qq kill [OPTIONS] JOB_ID...
JOB_ID… — One or more IDs of jobs to terminate. Optional.
If no JOB_ID and no directory are provided, qq kill searches for qq jobs in the current directory. If multiple suitable jobs are provided or found, qq kill terminates each one in turn.
By default, qq kill prompts for confirmation before terminating each job.
Without the --force flag, it will only attempt to terminate jobs that are queued, held, booting, or running — not jobs that are already finished or killed. When the --force flag is used, qq kill attempts to terminate any job regardless of its state, including jobs that qq believes are already finished or killed. This can be used to remove lingering or stuck jobs.
Options
-
-d,--dir— One or more directories to search for qq jobs in. Supports globs. -
-a,--all— Terminate all your unfinished jobs. -
-s,--server— Terminate jobs on the specified batch server. If not specified, the current server is used. Only used with--all. -
-y,--yes— Terminate the job(s) without asking for confirmation. -
--force— Forcefully terminate the job(s), ignoring its current state and skipping confirmation.
Examples
qq kill 123456
Terminates the job with ID 123456 located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the sever address.
Upon running this command, you will be prompted to confirm the termination by pressing y. This command only works if the specified job is a qq job with a valid and accessible info file, and the target batch server is reachable from the current machine.
qq kill 123456 144844 156432
Terminates jobs 123456, 144844, and 156432. You will be asked to confirm each termination individually.
qq kill
Terminates all suitable qq jobs whose info files are present in the current directory. You will be asked to confirm each termination individually.
qq kill 123456 -y
Terminates the job with ID 123456 without asking for confirmation (assumes ‘yes’).
qq kill 123456 --force
Forcefully terminates the job with ID 123456. This kills the job immediately and without confirmation, regardless of qq’s recorded job state.
qq kill -d /path/to/dir
Terminates the job which info file is located in the directory /path/to/dir.
qq kill -d /path/to/job*
Terminates all suitable jobs which info files are located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3). Useful for terminating job collections.
qq kill --all
Terminates all your qq jobs.
qq kill --all --server meta
Terminates all your uncompleted qq jobs associated with the Metacentrum batch server.
qq killall
Caution
This command is deprecated in qq v0.12. It will be removed completely in a future release of qq. Use
qq kill --allinstead.
The qq killall command is used to terminate all of your qq jobs. It is qq’s equivalent of Infinity’s pkillall.
Quick comparison with pkillall
qq killallcan only terminate jobs submitted usingqq submit; other jobs are not affected.
Description
Terminates all qq jobs submitted by the current user.
qq killall [OPTIONS]
This command only terminates qq jobs — other jobs in the batch system are not affected.
By default, qq killall prompts for confirmation before terminating the jobs.
Options
-y, --yes — Terminate all jobs without confirmation.
--force — Forcefully terminate all jobs, ignoring their current states and skipping confirmation.
-s TEXT, --server TEXT — Termine all your jobs on the specified batch server. If not specified, the current server is used.
Examples
qq killall
Terminates all your qq jobs with valid and accessible info files. You will be prompted to confirm termination by pressing y.
qq killall -y
Terminates all your qq jobs with valid and accessible info files without asking for confirmation (assumes “yes”).
qq killall --force
Forcefully terminates all your qq jobs with valid and accessible info files. No confirmation is requested, and the jobs will be terminated even if qq believes they are already finished, failed, or killed.
qq killall --server sokar
Terminate all your qq jobs with valid and accessible info files associated with the sokar batch server. You will be prompted to confirm termination by pressing y.
qq nodes
The qq nodes command displays the compute nodes available on the current batch server. It is qq’s equivalent of Infinity’s pnodes.
Quick comparison with pnodes
- The output of
qq nodesis more dynamically formatted than that ofpnodes. If an entire group of nodes lacks a specific attribute (e.g., no GPUs, no shared scratch storage), the corresponding column is hidden.- Node group assignments are always determined heuristically based on node names. A full match of the alphabetic part of the name is required for nodes to belong to the same group (unlike
pnodes, which uses partial matches).
Description
Displays information about the nodes managed by the batch system. By default, only nodes that are available to you are shown.
qq nodes [OPTIONS]
Nodes are grouped heuristically into node groups based on their names.
Options
-
-a,--all— Display all nodes, including those that are down, inaccessible, or reserved. -
-sTEXT,--serverTEXT— Show nodes for a specific batch server. If not specified, nodes for the default batch server are shown. -
--yaml— Output node metadata in YAML format.
Examples
qq nodes
Displays a summary of all nodes associated with the default batch server that are available to you.
This is what the output might look like (truncated):
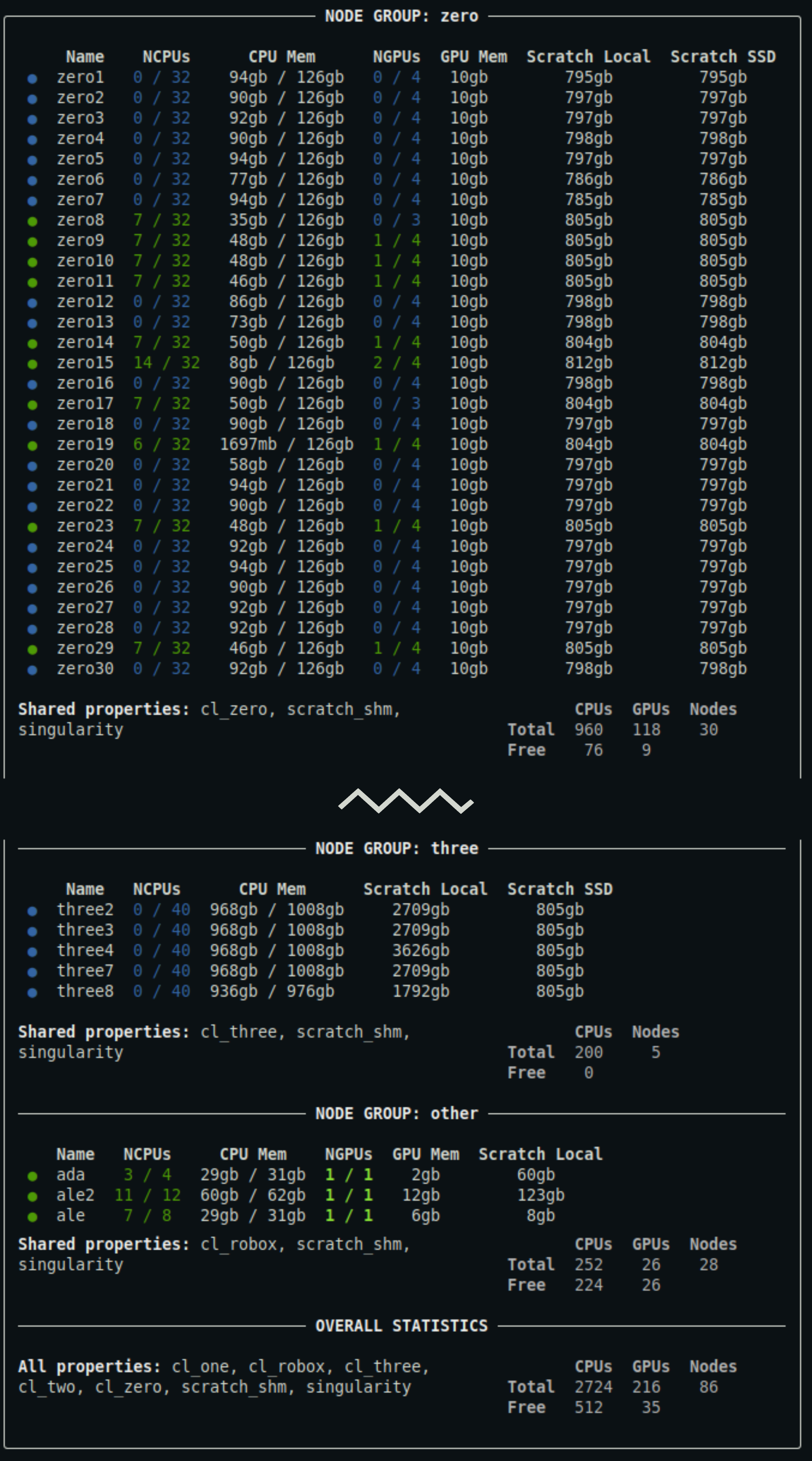
Output truncated. For a detailed description of the output, see below.
qq nodes --all
Displays a summary of all nodes associated with the default batch server, including those that are down, inaccessible, or reserved.
qq nodes --server sokar
Displays a summary of all nodes associated with the sokar batch server that are available to you. sokar is a known shortcut for the full batch server name sokar-pbs.ncbr.muni.cz. You can use either of them. For more information about accessing information from other clusters, read this section of the manual.
qq nodes --yaml
Prints a summary of all available nodes associated with the default batch server in YAML format. This output contains the full metadata provided by the batch system.
Notes
- The availability state of nodes is not always perfectly reliable. Occasionally, nodes that are actually unavailable may still be reported as available.
Description of the output
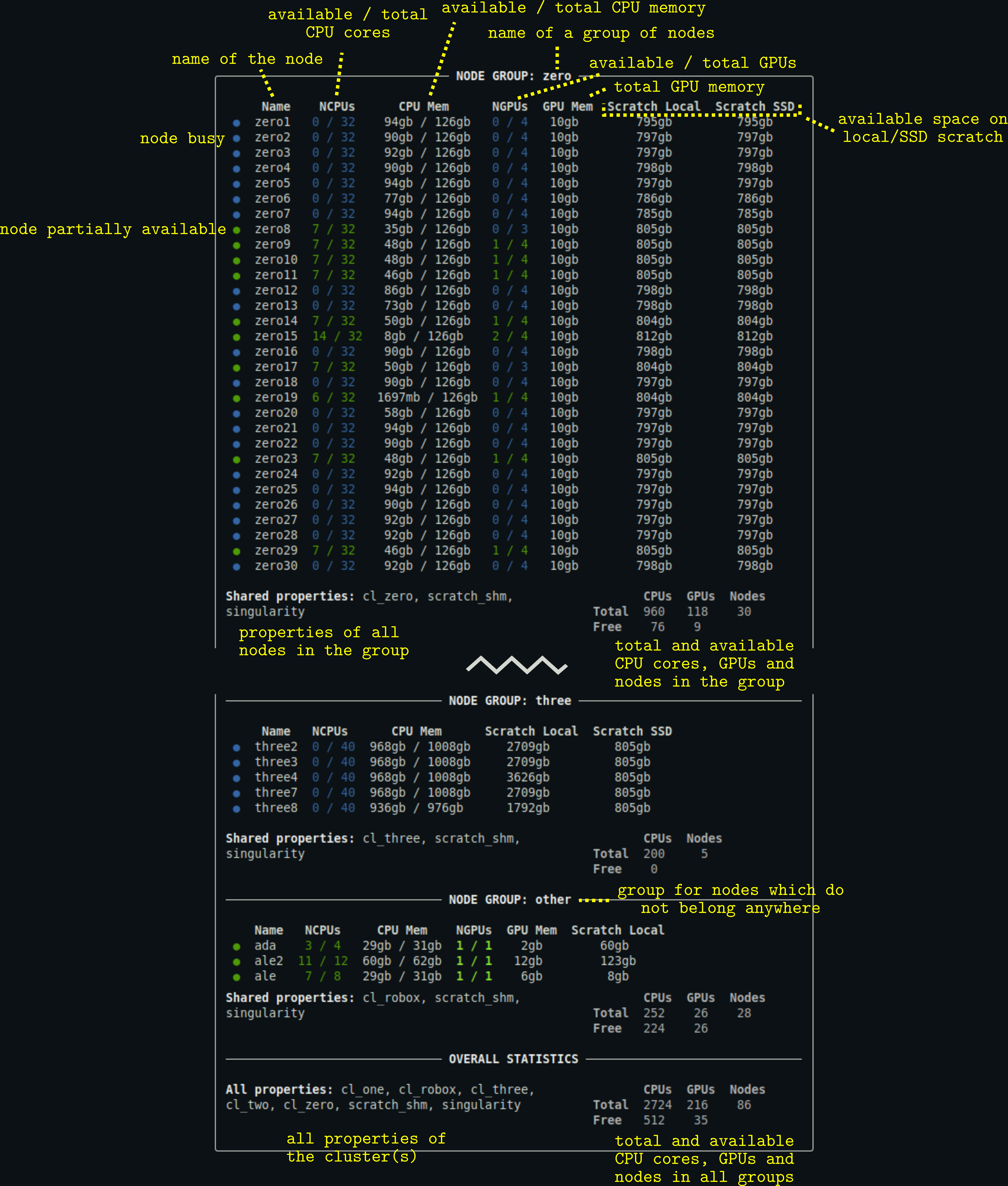
- You can customize the appearance of the output using a configuration file.
- Columns for resources that are not relevant to a given node group (e.g., when no node in the group has GPUs) are hidden.
- For some node groups, there may also be a
Scratch Sharedcolumn specifying the amount of scratch space available to be shared among the nodes.
qq queues
The qq queues command displays the queues available on the current batch server. It is qq’s equivalent of Infinity’s pqueues.
Quick comparison with pqueues
qq queuesis generally more accurate at identifying available and unavailable queues thanpqueues.- The only other notable difference is the output format.
Description
Displays information about the queues available on the current batch server. By default, only queues that are available to you are shown.
qq queues [OPTIONS]
Options
-
-a,--all— Display all queues, including those that are not available to you. -
-sTEXT,--serverTEXT— Show queues for a specific batch server. If not specified, queues for the default batch server are shown. -
--yaml— Output queue metadata in YAML format.
Examples
qq queues
Displays a summary of all queues associated with the default batch server to which you can submit jobs.
This is what the output might look like:
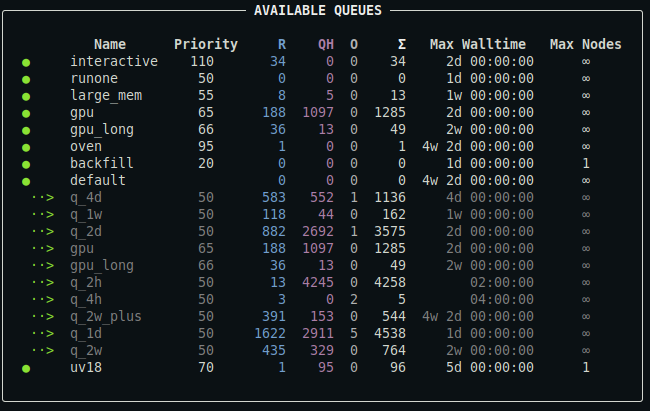
For a detailed description of the output, see below.
qq queues --all
Displays a summary of all queues associated with the default batch server, including those you cannot submit jobs to.
This is what the output might look like:
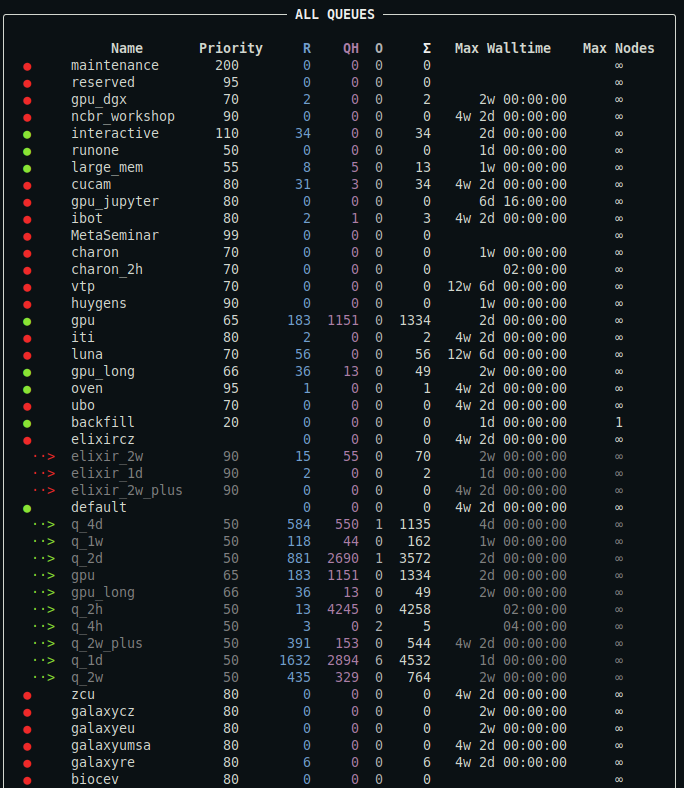
Output truncated. For a detailed description of the output, see below.
qq queues --server metacentrum
Displays a summary of all queues associated with the metacentrum batch server that are available to you. metacentrum is a known shortcut for the full batch server name pbs-m1.metacentrum.cz. You can use either of them. For more information about accessing information from other clusters, read this section of the manual.
qq queues --yaml
Prints a summary of all available queues in YAML format. This output contains the full metadata provided by the batch system.
Description of the output
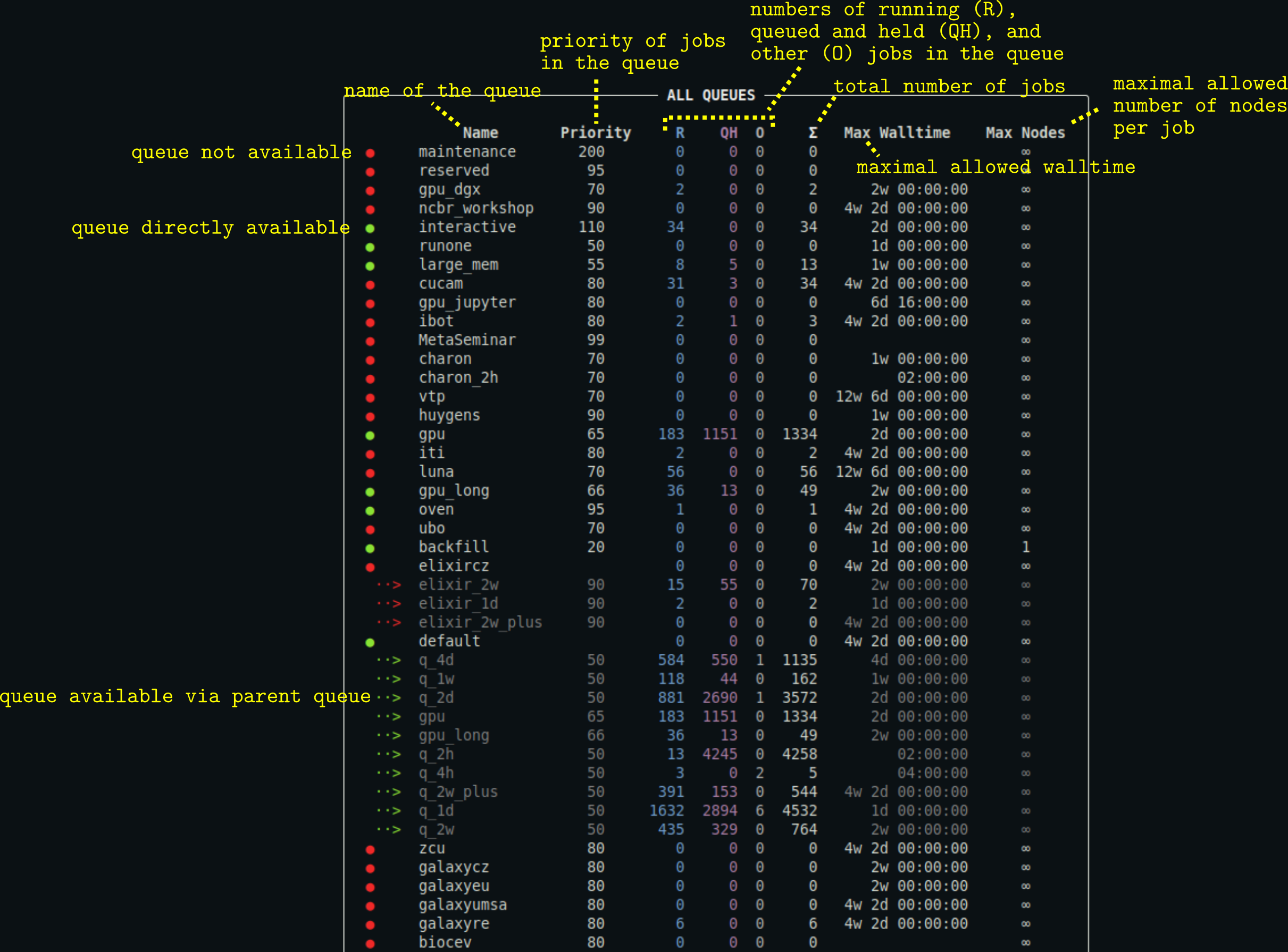
- You can customize the appearance of the output using a configuration file.
- The output may also contain the column
Commentproviding the comment associated with the queue (typically additional information about the queue). Max Nodescolumn is hidden if no queue defines a maximal allowed number of requested nodes per job.
qq respawn
The qq respawn command is used to “respawn” jobs, i.e. put failed or killed jobs back into the queue to be retried. It has no direct equivalent in Infinity.
Imagine you find that your job has failed because it unexpectedly reached a walltime limit (e.g., because it was running on a slow node). You want to just put the job back into the queue to be retried. Normally, you would run something like the following sequence of commands:
# go to the directory with the crashed job qq cd <crashed-job-id> # remove the working directory (optional) qq wipe # clear the runtime files from the crashed job qq clear # submit the job to the queue with the same parameters qq submit -q <queue> --ncpus 8 --ngpus 1 --walltime 1d <script-name>With
qq respawn, you can just run:# remove the working directory, clear runtime files, # and submit a new job with the original parameters qq respawn <crashed-job-id>
Description
Respawns the specified qq jobs, or all qq jobs in the specified directories.
qq respawn [OPTIONS] JOB_ID...
JOB_ID… — One or more IDs of jobs to respawn. Optional.
If no JOB_ID and no directory are provided, qq respawn searches for qq jobs in the current directory. If multiple suitable jobs are found, qq respawn respawns each one in turn.
Options
-d,--dir— One or more directories to search for qq jobs in. Supports globs.
Examples
qq respawn 123456
Respawns the job with ID 123456 located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the sever address.
Only failed and killed jobs can be respawned. If you try to respawn a job in any other state, you will get an error.
qq respawn 123456 144844 156432
Respawns jobs 123456, 144844, and 156432, if they are suitable.
qq respawn
Respawns all suitable qq jobs whose info files are present in the current directory (typically one, since qq requires one job per directory).
qq respawn -d /path/to/dir
Respawns all suitable qq jobs whose info files are present in direcotry /path/to/dir.
qq respawn -d /path/to/job*
Respawns all suitable qq jobs whose info files are located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3). Useful for managing job collections.
qq shebang
The qq shebang command is a utility for converting regular scripts into qq-compatible scripts. It has no direct equivalent in Infinity.
Description
Adds the qq run shebang to a script, or replaces an existing one. If no script is specified, it simply prints the qq run shebang to standard output.
qq shebang [OPTIONS] SCRIPT
SCRIPT — Path to the script to modify. This argument is optional.
Examples
Suppose we have a script named run_script.sh with the following content:
#!/bin/bash
# activate the Gromacs module
metamodule add gromacs/2024.3-cuda
# prepare a TPR file
gmx_mpi grompp -f md.mdp -c eq.gro -t eq.cpt -n index.ndx -p system.top -o md.tpr
# run the simulation using 8 OpenMP threads
gmx_mpi mdrun -deffnm md -ntomp 8 -v
This script cannot be submitted using qq submit because it lacks the qq run shebang.
By running:
qq shebang run_script.sh
the existing bash shebang is replaced with the qq run shebang, resulting in:
#!/usr/bin/env -S qq run
# activate the Gromacs module
metamodule add gromacs/2024.3-cuda
# prepare a TPR file
gmx_mpi grompp -f md.mdp -c eq.gro -t eq.cpt -n index.ndx -p system.top -o md.tpr
# run the simulation using 8 OpenMP threads
gmx_mpi mdrun -deffnm md -ntomp 8 -v
If you run qq shebang without specifying a script (you use just qq shebang), it simply prints the qq shebang to standard output:
#!/usr/bin/env -S qq run
qq run
The qq run command represents the execution environment in which a qq job runs. It is qq’s equivalent of Infinity’s infex script and the infinity-env.
You should not invoke qq run directly. Instead, every script submitted with qq submit must include the following shebang line:
#!/usr/bin/env -S qq run
For more details about what qq run does, see the sections on standard jobs and loop jobs.
Quick comparison with infex and infinity-env
- Like
infinity-env, using theqq runshebang prevents you from accidentally running the script directly.- Unlike Infinity, all qq jobs must use this execution environment — no separate helper run script is created when submitting a qq job.
qq runalso takes over the responsibilities ofparchiveandpresubmit, which have no direct equivalents in qq.
qq stat
The qq stat command displays information about jobs from all users. It is qq’s equivalent of Infinity’s pqstat.
Quick comparison with pqstat
- The same differences that apply between
qq jobsandpjobsalso apply here.
Description
Displays a summary of jobs from all users. By default, only uncompleted jobs are shown.
qq stat [OPTIONS]
Options
-
-e,--extra— Include extra information about the jobs. -
-a,--all— Include both uncompleted and completed jobs in the summary. -
-sTEXT,--serverTEXT— Show jobs for a specific batch server. If not specified, jobs on the default batch server are shown. -
--yaml— Output job metadata in YAML format.
Examples
qq stat
Displays a summary of all uncompleted (queued, running, or exiting) jobs associated with the default batch server. The display looks similar to the display of qq jobs.
qq stat -e
Includes extra information about the jobs in the output: the input machine (if available), the input directory, and the job comment (if available).
qq stat --all
Displays a summary of all jobs associated with the default batch server, both uncompleted and completed. Note that the batch system eventually removes records of completed jobs, so they may disappear from the output over time.
qq stat --server sokar
Displays a summary of all uncompleted jobs associated with the sokar batch server that are available to you. sokar is a known shortcut for the full batch server name sokar-pbs.ncbr.muni.cz. You can use either of them. For more information about accessing information from other clusters, read this section of the manual.
qq stat --yaml
Prints a summary of all unfinished jobs in YAML format. This output contains all metadata provided by the batch system.
Notes
- This command lists all types of jobs, including those submitted using
qq submitand jobs created through other tools. - The run times and job states may not exactly match the output of
qq info, sinceqq statrelies solely on batch system data and does not use qq info files.
qq submit
The qq submit command is used to submit qq jobs to the batch system. It is qq’s equivalent of Infinity’s psubmit.
Quick comparison with psubmit
qq submitdoes not ask for confirmation; it behaves likepsubmit (...) -y.Options and parameters are specified differently. The only positional argument is the script name — everything else is an option. You can see all supported options using
qq submit --help.Infinity:
psubmit cpu run_script ncpus=8,walltime=12h,props=cl_zero -yqq:
qq submit -q cpu run_script --ncpus 8 --walltime 12h --props cl_zeroOptions can also be specified directly in the submitted script, or as a mix of in-script and command-line definitions. Command-line options always take precedence.
Unlike with
psubmit, you do not have to executeqq submitdirectly from the directory with the submitted script. You can runqq submitfrom anywhere and provide the path to your script. The job’s input directory will always be the submitted script’s parent directory. Additionally,qq submitcan submit multiple jobs at once.
qq submithas better support for multi-node jobs thanpsubmitas it allows specifying resource requirements per requested node.
Description
Submits one or more qq jobs to the batch system.
qq submit [OPTIONS] SCRIPT...
SCRIPT… — One or more paths to the scripts to submit.
The submitted script(s) must contain the qq run shebang. You can add it to your script by running qq shebang SCRIPT.
When the job is successfully submitted, qq submit creates a .qqinfo file for tracking the job’s state.
Options
General settings
-q, --queue TEXT — Name of the queue to submit the job to.
-s, --server TEXT — Name of the batch server to submit the job to. If not specified, the job is submitted to the default batch server. Only supported on Metacentrum-family clusters. Read more about specifying a server here.
--account TEXT — Account to use for the job. Required only in environments with accounting (e.g., IT4Innovations).
--job-type TEXT — Type of the job. Defaults to standard. Available types: ‘standard’, ‘loop’, ‘continuous’. Read more about job types here.
--exclude TEXT — Colon-, comma-, or space-separated list of files or directories that should not be copied to the working directory. Paths must be relative to the input directory.
--include TEXT — Colon-, comma-, or space-separated list of files or directories to copy into the working directory in addition to the input directory contents. These files are not copied back after job completion. Paths must be absolute or relative to the input directory. Ignored if the input directory is used as the working directory.
--depend TEXT — Comma- or space-separated list of job dependencies in the format ‘
--transfer-mode TEXT — Colon-, comma-, or space-separated list of transfer modes controlling when working directory files are transferred to the input directory. Modes: success (exit code 0), failure (non-zero exit code), always, never, or a specific exit code number (e.g., 42). Combine modes; files transfer if any apply. Defaults to success. On transfer, the working directory is deleted; otherwise it is preserved. Killed jobs are never transferred automatically. Ignored if the input directory is used as the working directory. Examples: ‘success’, ‘always’, ‘success:42’, ‘1 2 3’. Read more about transfer modes here.
--interpreter TEXT — Executable name or absolute path of the interpreter used to run the submitted script, including options for the interpreter. The interpreter must be available on the computing node. Defaults to bash. Read more about specifying interpreters here.
--batch-system TEXT — Name of the batch system used to submit the job. If not specified, the value of the environment variable ‘QQ_BATCH_SYSTEM’ is used or the system is auto-detected.
Requested resources
Memory and storage sizes are specified as ‘N
Job resources are described in more detail in the Job resources section.
--nnodes INTEGER — Number of nodes to allocate for the job.
--ncpus-per-node INTEGER — Number of CPU cores to allocate per node.
--ncpus INTEGER — Total number of CPU cores to allocate for the job. Overrides –ncpus-per-node.
--mem-per-cpu TEXT — Memory to allocate per CPU core.
--mem-per-node TEXT — Memory to allocate per node. Overrides –mem-per-cpu.
--mem TEXT — Total memory to allocate for the job. Overrides –mem-per-cpu and –mem-per-node.
--ngpus-per-node INTEGER — Number of GPUs to allocate per node.
--ngpus INTEGER — Total number of GPUs to allocate for the job. Overrides –ngpus-per-node.
--walltime TEXT — Maximum runtime for the job. Examples: ‘1d’, ‘12h’, ‘10m’, ‘24:00:00’.
--work-dir, --workdir TEXT — Type of working directory to use for the job. Available types depend on the environment.
--work-size-per-cpu, --worksize-per-cpu TEXT — Storage to allocate per CPU core.
--work-size-per-node, --worksize-per-node TEXT — Storage to allocate per node. Overrides –work-size-per-cpu.
--work-size, --worksize TEXT — Total storage to allocate for the job. Overrides –work-size-per-cpu and –work-size-per-node.
--props TEXT — Colon-, comma-, or space-separated list of node properties required (e.g., cl_two) or prohibited (e.g., ^cl_two) to run the job.
Settings for continuous and loop jobs
Only used when job-type is continuous or loop.
--resubmit-from TEXT — Colon-, comma-, or space-separated ordered list of hosts to try resubmitting from. The job is resubmitted from the first reachable host. Allowed values: input (the submission machine), working (the execution node), or a specific hostname (e.g., perian.metacentrum.cz). Default value depends on the batch system. Examples: ‘input’, ‘input,working’, ‘input:st1:st2’, ‘working perian.metacentrum.cz’. Read more about resubmission hosts here.
Settings for loop jobs
Only used when job-type is loop.
--loop-start INTEGER — Starting cycle for a loop job. Defaults to 1.
--loop-end INTEGER — Ending cycle for a loop job.
--archive TEXT — Directory name for archiving files from a loop job. Defaults to storage.
--archive-format TEXT — Filename format for archived files. Defaults to job%04d.
--archive-mode TEXT — Colon-, comma-, or space-separated list of archive modes controlling when working directory files are archived upon job completion. Supports the same modes as –transfer-mode. Defaults to success.
Specifying options in the script
Instead of specifying submission options on the command line, you can include them directly in the script using qq directives.
qq directives follow this format: # qq <option>=<value> or # qq <option> <value> (both are equivalent).
The word qq is case-insensitive (qq, QQ, Qq, and qQ are all valid), and spacing is flexible.
All qq directives must appear at the beginning of the script, before any executable commands.
Example:
#!/usr/bin/env -S qq run
# qq queue gpu
# qq job-type loop
# qq loop-end 10
# qq archive storage
# qq archive-format md%04d
# qq ncpus 8
# qq ngpus 1
# qq walltime 1d
metamodule add ...
Note
In the example above, kebab-case is used for option names, but qq directives also support snake_case, camelCase, and PascalCase. For example:
# qq job-type loop,# qq job_type loop,# qq jobType loop, and# qq JobType loopare all equivalent.
All options of qq submit can be defined within the script body. Options that have a short form, such as -q/--queue and -s/--server, must be written in their long form (e.g., # qq queue gpu instead of # qq q gpu).
Command-line options always take precedence over options defined in the script body.
Submitting multiple jobs
You can submit multiple jobs by providing multiple script paths to qq submit. The command line options will apply to all submitted scripts, but each script can also define its own qq directives. Note however that command line options override options defined in the script body.
Submission of multiple jobs is parallelized and consequently much faster than submitting them one by one. Note however, that the order of the jobs is not guaranteed to be preserved, i.e. a script which you provide later in the list of scripts may be submitted before a script which you provided earlier.
Examples
qq submit run_script.sh -q cpu --ncpus 8 --workdir scratch_local --worksize-per-cpu 2gb --walltime 2d --props hyperthreading
Submits the script run_script.sh to the cpu queue, requesting 8 CPU cores and 16 GB of local scratch space (2 GB per core). The requested walltime is 48 hours, and the job must run on a node with the hyperthreading property. Additional options may come from the script or queue defaults, but command-line options take precedence.
qq submit run_script.sh
Submits the script run_script.sh, taking all submission options from the script itself or from queue/server defaults.
qq submit job*/run_script.sh -q cpu --ncpus 8 --walltime 1d
Submits all run_script.sh scripts in the job* directories (e.g., job1/run_script.sh, job2/run_script.sh) to the cpu queue, requesting 8 CPU cores and a walltime of 1 day for each of them. Additional parameters may be specified inside the individual scripts. The submitted jobs are completely independent of each other.
qq sync
The qq sync command fetches files from a job’s working directory to its input directory. It is qq’s equivalent of Infinity’s psync.
Quick comparison with psync
- Unlike
psync,qq syncfetches all files from the working directory by default.- You can use
qq syncwith a job ID to fetch files from the job’s working directory to its input directory without having to actually navigate to its input directory. You can even provide IDs of multiple jobs.- You can provide
qq syncwith one or more directories to search for qq jobs in. Files for all discovered jobs are then fetched from their working directories.- If you want to fetch only specific files, you cannot select them interactively — you must provide a list of filenames when running
qq sync.
Description
Fetches files from the working directories of the specified qq jobs, or from the working directories of the jobs submitted from the specified directories.
qq sync [OPTIONS] JOB_ID...
JOB_ID.,. — One or more IDs of jobs whose working directory files should be fetched. Optional
If no JOB_ID and no directory are provided, qq sync searches for qq jobs in the current directory. If multiple suitable jobs are found, qq sync fetches files from each one in turn. Files fetched from later jobs may overwrite files from earlier ones in the input directory.
Files are copied from the job’s working directory to its input directory, not to the current directory.
Options
-
-d,--dir— One or more directories to search for qq jobs in. Supports globs. -
-a,--all— Fetch files for all your unfinished jobs. -
-s,--server— Operate on jobs from the specified batch server. If not specified, the current server is used. Only used with--all. -
-f,--filesTEXT— A colon-, comma-, or space-separated list of files and directories to fetch. If not specified, the entire content of the working directory is fetched.
Examples
qq sync 123456
Fetches all files from the working directory of the job with ID 123456 to that job’s input directory. If you use just the numerical portion of the job ID, the job is assumed to be located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the server address.
This command only works if the specified job is a qq job with a valid and accessible info file, and if the batch server and main node are reachable from the current machine.
qq sync 123456 144844 156432
Fetches all files from the working directories of jobs 123456, 144844, and 156432 to their respective input directories.
qq sync
Fetches all files from the working directories of all jobs whose info files are present in the current directory.
qq sync 123456 -f file1.txt,file2.txt,file3.txt
Fetches file1.txt, file2.txt, and file3.txt from the working directory of the job with ID 123456 to its input directory. All other files are ignored. Missing files are skipped without error.
qq sync -d /path/to/dir
Feteches all files from the working directories of all jobs whose info files are present in directory /path/to/dir.
qq sync -d /path/to/job*
Fetches all files from the working directories of all jobs located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3). Files are always fetched to the corresponding job’s input directory. Useful for managing job collections.
qq sync --all
Fetches files for all your running jobs.
qq sync --all --server meta
Fetches files for all your running jobs associated with the Metacentrum batch server.
qq wipe
The qq wipe command is used to delete working directories of qq jobs. It has no direct equivalent in Infinity.
Tip
It can be tricky to remember the difference between
qq wipeandqq clear. This might be useful: Wipe affects the Working directory.
Description
Deletes the working directories of the specified qq jobs, or of all qq jobs in the specified directories.
qq wipe [OPTIONS] JOB_ID...
JOB_ID — One or more IDs of jobs whose working directories should be deleted. Optional.
If no JOB_ID and no directory are specified, qq wipe searches for qq jobs in the current directory.
By default, qq wipe prompts for confirmation before deleting the working directory for each job.
Without the --force flag, it will only attempt to delete working directories of jobs that have failed or been killed. When the --force flag is used, qq wipe attempts to wipe the working directory of any job regardless of its state, including jobs that are queued, running or successfully finished. You should be very careful when using this option as it may delete useful data or cause your job to crash!
Note
If the working directory matches the input directory,
qq wipewill never delete it, even if you use the--forceflag, to protect you from accidentally removing your data.
Options
-
-d,--dir— One or more directories to search for qq jobs in. Supports globs. -
-y,--yes— Delete the working directory without confirmation. -
--force— Delete the working directory of the job forcibly, ignoring its current state and without confirmation.
Examples
qq wipe 123456
Deletes the working directory of the job with ID 123456 located on the default batch server. If the job is located on a different batch server, you need to use the full ID including the server address.
Upon running the command, you will be prompted to confirm the termination by pressing y. This command only works if the specified job is a qq job with a valid and accessible info file, and the batch server must be reachable from the current machine.
qq wipe 123456 144844 156432
Deletes the working directories of the jobs 123456, 144844 and 156432. You will be asked to confirm each deletion individually.
qq wipe
Deletes the working directories of all suitable qq jobs whose info files are present in the current directory. You will be asked to confirm each deletion individually.
qq wipe 123456 -y
Deletes the working directory of the job with ID 123456 without asking for confirmation (assumes ‘yes’).
qq wipe 123456 --force
Forcefully deletes the working directory of the job with ID 123456. This deletes the working directory no matter the state of the job. This is dangerous — only use the --force flag if you are absolutely sure you know what you are doing!
qq wipe -d /path/to/dir
Deletes working directories of all suitable qq jobs whose info files are present in direcotry /path/to/dir. Asks for confirmation before deleting each working directory.
qq wipe -d /path/to/job* -y
Deletes working directories of all suitable qq jobs located in directories matching the glob pattern /path/to/job* (e.g., /path/to/job1, /path/to/job2, /path/to/job3) without asking for confirmation (assumes ‘yes’).
Job collections
Imagine you have a large number of related jobs to manage — for instance a set of windows of an umbrella sampling simulation, a large number of replicas of some simulation system, or just a set of related systems with slightly different simulation parameters. How do you manage them easily? You might think of array jobs, a concept available in both batch systems that qq is built on (PBS and Slurm). Unfortunately, qq does not support array jobs. This may change in the future, but for now qq focuses on a simpler and more flexible alternative: job collections.
A job collection is a group of independent, but typically related jobs whose input directories typically live near each other in the filesystem. Since qq requires one job per directory, a job collection is essentially a group of directories — for example, a set of subdirectories sharing a common parent.
That said, collections do not actually exist in qq. There is no registry, no named group, and no explicit membership to manage. Instead, a collection is whatever set of directories you point qq at. qq operator commands accept multiple directory paths at once, so you can treat any group of jobs as a single unit simply by selecting the right paths — usually with a glob pattern.
Note
This approach is intentionally different from NCBR’s Infinity ABS, where job collections are named groups with explicit membership that the user must maintain. While named collections have their advantages, they come with overhead: you have to remember to add each job to the collection when submitting it and to remove it when it no longer belongs, and of course you have to name the collections appropriately, so you can make sense of them.
qq takes the opposite stance: job collections are implicit and ephemeral, defined by your filesystem structure and the paths you provide at the command line. You can form any grouping you like, at any time, without any bookkeeping at all.
Working with job collections
All qq commands operating on jobs accept multiple directory paths, so working with a collection requires nothing beyond a glob pattern.
Imagine you are running a set of simulations in a single parent directory, each in its own subdirectory named job01, job02, job03, and so on.
Submit the entire collection by passing multiple scripts to qq submit:
qq submit job*/script.sh (...)
Check the status of all jobs in the collection with qq info:
qq info -d job*
For large collections, the brief output might be more readable:
qq info -d job* --brief
Terminate the entire collection with qq kill:
qq kill -d job* -y
Or target only specific jobs:
qq kill -d job01 job03 -y
Tip
The
-yflag skips the confirmation prompt. Without it, qq asks you to confirm each termination individually.
If some jobs fail, respawn them with qq respawn:
qq respawn -d job*
Tip
You can provide paths to the full collection.
qq respawnautomatically skips jobs that are queued, running, or completed successfully — only failed or killed jobs are resubmitted.
To clear runtime files for all jobs in the collection, use qq clear:
qq clear -d job*¨
Tip
qq clearwill not remove runtime files for active or successfully finished jobs. You can therefore also safely use it on the entire job collection.
Commands qq go, qq sync, and qq wipe work the same way and are documented in their respective sections.
Advanced topics
This section covers less common but occasionally essential features of qq — things you may not need for everyday use, but that give you greater control over how your jobs are submitted and executed.
Transferring files from the working directory
As described in various sections of this manual, if your job creates its own working directory (e.g., on scratch), the data produced during the job’s execution are transferred back to the input directory only if the job finishes successfully (with exit code 0, or the value of the QQ_NO_RESUBMIT environment variable in the case of loop/continuous jobs). The working directory is then removed and can no longer be accessed.
If the job fails (i.e., finishes with an exit code other than 0), no data are transferred to the input directory (except for qq runtime files). Instead, the files remain in the working directory. You can then navigate to the working directory to determine what went wrong using qq go, fetch the data manually using qq sync, or delete the working directory using qq wipe.
In some situations, it may be useful to automatically transfer files even from failed jobs. In other cases, you may want the opposite behavior—never transfer files automatically and always keep them in the working directory. To support these use cases, qq allows you to specify a transfer mode when submitting a job. The transfer mode determines how file transfer should be handled.
For example, to always transfer files from the working directory, submit a job with the --transfer-mode always option:
qq submit -q default --ncpus 8 --walltime 1d --transfer-mode always my_script.sh
With this setting, files are transferred from the working directory to the input directory regardless of whether the job succeeds or fails. The working directory is then removed.
Warning
Files are never transferred if the job is killed by you, the administrator, or the system, regardless of the specified transfer mode. Similarly, in the case of a qq error (job exit codes 90–99), data may not be transferred even if explicitly requested. In these situations, you can still access the data using
qq goorqq sync, unless the working directory has already been deleted.
Note
Specifying a transfer mode only makes sense when the working directory is different from the input directory (i.e., when you are not using the
--work-dir input_diroption). If the job runs directly in the input directory, no file transfer is performed.
Transfer modes
Transfer modes can be divided into keyword transfer modes and numerical transfer modes.
There are four keyword transfer modes:
-
success
The default mode. If you do not specify a transfer mode, this one is used. Files are transferred from the working directory only if the job finishes successfully (exit code0). -
failure
Files are transferred from the working directory only if the job fails (exit code not equal to0). -
always
Files are transferred from the working directory regardless of the job’s exit code. Files are not transferred if the job is killed. -
never
Files are never transferred from the working directory, regardless of the job’s exit code. All files remain in the working directory, which is therefore not removed.
Numerical transfer modes specify the exact exit code that the job must finish with for the files to be transferred. For example, transfer mode 0 means that files are transferred only if the job exits with code 0—in other words, transfer mode 0 is equivalent to success. Transfer mode 1 transfers files only if the exit code is 1, and transfer mode 42 transfers files only if the exit code is 42.
This allows you to specify precisely which exit conditions should trigger file transfer from the working directory, especially when combined with the feature described below.
Specifying multiple transfer modes
You can specify multiple transfer modes for qq submit by separating them with commas, colons, or spaces. If the condition for any of the specified transfer modes is satisfied, the files are transferred and the working directory is removed.
For example, to transfer files if the job finishes successfully or with exit code 3 or 4:
qq submit -q default (...) --transfer-mode success,3,4 my_script.sh
Archive modes
Transfer mode does not affect how files are archived in loop jobs. For example, if you run a loop job with --transfer-mode always and the job fails, archiving is not performed and all files from the working directory are transferred to the input directory.
If you want files to be archived even when a loop job fails, you must also specify --archive-mode. For example:
qq submit -q default (...) --transfer-mode always --archive-mode always qq_loop_md
The same modes are available for --archive-mode as for --transfer-mode (see above).
Tip
Remember that all qq options, including
--transfer-modeand--archive-mode, can also be specified inside the submitted script using qq directives. You can also set the default transfer and archive mode for your jobs in the QQ_CONFIG file (this needs to be done on all machines from which you submit jobs).
Specifying job dependencies
Occasionally, you may want your submitted job to start only after some condition related to the state of some other job(s) is fulfilled. You can control when the job should start being executed using the --depend option of qq submit.
As the value for this option, you can provide a list of comma- or space-separated job dependencies in this format:
<dependency_type>=<job_id>[:<job_id>...]
A job that is waiting for its dependencies to be satisfied is in a held state.
Dependency types
The dependency type specifies the condition that the given jobs need to fulfill for the newly submitted job to start. There are currently four supported types:
after— the submitted job can start only after the specified job has startedafterok— the submitted job can start only after the specified job has finished successfullyafternotok— the submitted job can start only after the specified job has failed or been killedafterany— the submitted job can start only after the specified job has completed (either successfully, unsuccessfully, or been killed)
Specifying multiple job IDs
For a single dependency type, you can provide either a single job ID or multiple colon-separated job IDs. For example, after=412643 means that the job with ID 412643 needs to start before the submitted job can start, while after=412643:412644:412645 means that all three specified jobs need to start before the submitted job can start.
Specifying multiple dependency types
If your job should start only after multiple different conditions are fulfilled, you can provide multiple dependency expressions separated by commas or spaces. For example:
qq submit (...) --depend after=412643,afterok=412777:412779
means that the submitted job can start only after all of the following is true:
- the job 412643 has started,
- the jobs 412777 and 412779 have finished successfully.
Submitting non-bash scripts
When you submit a qq job using qq submit, the submitted script is executed using a special qq run interpreter. This interpreter does not just run the script, but also performs many operations related to job preparation: for example, it creates the working directory for the job, transfers files, and, in the case of loop jobs, also archives files and resubmits jobs. To execute the actual commands in the submitted script, qq run uses the standard Linux bash shell by default. That’s why you typically write your script in bash with a qq run shebang and potentially some qq directives.
However, with qq you can also specify a different interpreter than bash to execute the commands in your submitted script. This means you don’t need to write a wrapper around e.g. your Python script — you can submit the script itself and tell qq: “Run it using Python”.
To control what interpreter qq run uses to execute the submitted script, specify the --interpreter option of qq submit. For example, to submit a Python script, you can run:
qq submit my_script.py (...) --interpreter python
The script my_script.py will be executed using python. You need to make sure that Python is available on the compute node where your job is to be executed, otherwise your job will fail. Also make sure that the python executable on the compute node starts the Python interpreter of the expected version with the expected packages your script requires.
If you want to provide arguments to your interpreter, you can do that as follows:
qq submit my_script.py (...) --interpreter "python -u -O"
The script my_script.py will be executed using python with unbuffered output (-u) and optimized mode enabled (-O).
Important
No matter what interpreter you want your script to be run with, you must always include the standard qq run shebang:
#!/usr/bin/env -S qq run. You can easily add it to your script usingqq shebang.
Submitting a simple Python script
Let’s look at a more complete and concrete example. Suppose we have a simple Python script estimating the value of π using a Monte Carlo simulation.
#!/usr/bin/env -S qq run
# qq interpreter python
"""Estimate the value of pi using the Monte Carlo method."""
import random
N_SAMPLES = 1_000_000
def estimate_pi(n_samples: int) -> float:
inside = 0
for _ in range(n_samples):
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
if x**2 + y**2 <= 1:
inside += 1
return 4 * inside / n_samples
def main():
print(f"Estimating pi using {N_SAMPLES:,} samples...")
result = estimate_pi(N_SAMPLES)
print(f"Estimated pi: {result:.6f}")
print(f"Actual pi: {3.141593:.6f}")
print(f"Error: {abs(result - 3.141593):.6f}")
if __name__ == "__main__":
main()
We save the script into a file calc_pi.py and submit it to the batch system:
qq submit -q default --ncpus 1 calc_pi.py
We do not need to specify the Python interpreter on the command line, as it is already specified in the body of the script using the qq directive # qq interpreter python. Upon submission and job start, everything happens as usual — including the creation of the working directory — but the script is interpreted using Python. Once the script finishes, the clean-up happens as for other qq jobs. The result of the calculation will be stored in calc_pi.out in the input (submission) directory once the job finishes.
Note
Here we are using the Python executable name (just
python), which is automatically expanded using thewhichcommand to the full path of the interpreter on the compute node (e.g.,/usr/bin/python). If you do not trust this automatic expansion, you can always specify the full path to the interpreter yourself (e.g.,# qq interpreter /usr/bin/pythonor# qq interpreter /path/to/my/own/python/on/shared/storage).
Submitting a looping Python script
With qq, you can run loop jobs even when using a non-bash interpreter. Loop jobs are useful when your script takes a very long time to finish and you have a mechanism to restart from checkpoints.
#!/usr/bin/env -S qq run
# Example qq loop job script written in Python.
#
# This script performs a fake iterative calculation across multiple cycles,
# demonstrating how to use qq python loop jobs with checkpointing. Each cycle loads
# the running state from a checkpoint file written by the previous cycle,
# performs a fixed number of iterations that increment a running total, writes
# the results for the current cycle, and writes a checkpoint for the next one.
# On the first cycle, the state is initialized from scratch.
# qq interpreter python
# qq job-type loop
# qq loop-end 10
# qq archive storage
# qq archive-format job%04d
import os
import json
########################################
# Calculation options #
########################################
# number of iterations of the fake calculation per cycle
ITERATIONS_PER_CYCLE = 1000
# increment added to the running total in each iteration
INCREMENT = 0.01
########################################
# Execution section #
########################################
# read qq environment variables
loop_current = int(os.environ["QQ_LOOP_CURRENT"])
loop_start = int(os.environ["QQ_LOOP_START"])
archive_format = os.environ["QQ_ARCHIVE_FORMAT"]
# format the current and next cycle file prefixes
curr = archive_format % loop_current
next_ = archive_format % (loop_current + 1)
print(f"Starting cycle {loop_current}.")
# load state from checkpoint if this is not the first cycle
if loop_current == loop_start:
print(f"First cycle - initializing state.")
total = 0.0
iteration = 0
else:
checkpoint_file = f"{curr}.json"
print(f"Loading checkpoint from '{checkpoint_file}'.")
with open(checkpoint_file) as f:
state = json.load(f)
total = state["total"]
iteration = state["iteration"]
print(f"Resuming from iteration {iteration}, total = {total:.4f}.")
# perform some fake calculation
print(f"Running {ITERATIONS_PER_CYCLE} iterations...")
for i in range(ITERATIONS_PER_CYCLE):
total += INCREMENT
iteration += 1
print(f"Cycle {loop_current} done. Iteration = {iteration}, total = {total:.4f}.")
# write the results for this cycle
results_file = f"{curr}.txt"
print(f"Writing results to '{results_file}'.")
with open(results_file, "w") as f:
f.write(f"Cycle: {loop_current}\n")
f.write(f"Iteration: {iteration}\n")
f.write(f"Total: {total:.6f}\n")
# write the checkpoint for the next cycle
# this file must be written so that qq can determine the next cycle number
checkpoint_file = f"{next_}.json"
print(f"Writing checkpoint to '{checkpoint_file}'.")
with open(checkpoint_file, "w") as f:
json.dump({"total": total, "iteration": iteration}, f)
print(f"Cycle {loop_current} finished successfully.")
We save the script into a file loop_job.py and submit it to the batch system:
qq submit -q default --ncpus 1 loop_job.py
The job is a regular qq loop job with the script interpreted using Python. Once a cycle finishes successfully, the next one is automatically submitted until the job reaches cycle number 10 (# qq loop-end 10). Files are archived according to standard qq rules for file archiving.
Warning
If the language you are writing the script in does not interpret lines starting with
#as comments (e.g., Octave, Lua), you cannot use qq directives, including the# qq interpreterdirective. In that case, you can still — and in fact must — specify all submission options on the command line when submitting the script.
Inter-cluster job management
Clusters of the Metacentrum family (Robox, Sokar, and Metacentrum clusters) use a compatible environment and are somewhat interconnected. Consequently, while connected to a computer of the Robox cluster, you can reach not just the default Robox batch server, but also the batch servers of Sokar and Metacentrum. You can therefore monitor, submit, kill, and manage jobs on all of these clusters directly from your Robox desktop.
Supported servers
The supported Metacentrum-family batch servers are:
robox-pro.ceitec.muni.cz(default for the Robox cluster)sokar-pbs.ncbr.muni.cz(default for the Sokar cluster)pbs-m1.metacentrum.cz(default for the Metacentrum clusters)
You can provide any of these server names as an option to any qq command that supports it — namely, qq jobs, qq stat, qq queues, qq nodes, and qq submit.
Alternatively, you can use one of the following shortcuts:
robox, which expands torobox-pro.ceitec.muni.czsokar, which expands tosokar-pbs.ncbr.muni.czmetacentrumormeta, which both expand topbs-m1.metacentrum.cz
Warning
Not all batch servers are necessarily accessible from all machines. For instance, from the Sokar frontend you cannot connect to
robox-pro.ceitec.muni.cz. However, all of the above batch servers should be reachable from any Robox desktop.
qq jobs, qq stat, qq queues, qq nodes
You can retrieve information about jobs, queues, and nodes associated with a different batch server by specifying the --server option (or its short form -s).
For example, when connected to a Robox computer, you can list your active jobs submitted to the Metacentrum clusters using:
qq jobs --server pbs-m1.metacentrum.cz
or using a shortcut:
qq jobs --server meta
Similarly, you can get information about all jobs of all users on the Sokar cluster:
qq stat -s sokar --all
Note
When you run
qq jobsorqq statwithout specifying a server (so that the jobs are collected for the default server), the “Job ID” column shows only the numerical portion of the job ID. When you run these commands with a server specified, you get the full job ID including the batch server address. This can be useful for the commands described below.
You can also get information about queues and compute nodes available on another server:
qq queues -s <server-name>
qq nodes -s <server-name>
qq submit
Caution
This feature is experimental and may be unstable. Tread carefully and report any issues or suspicious behavior you encounter.
Apart from monitoring jobs on different servers, you can also submit jobs to them. To do so, specify the --server (-s) option when submitting the job.
For example, you can submit a job from a Robox desktop to the Sokar cluster like this:
qq submit -q default --ncpus 8 --walltime 12h --server sokar my_job.sh
Note that you are submitting to a queue on the Sokar cluster, so you need to use a queue that is available there.
Important
If you submit a job to a different cluster, you need to have qq installed on this cluster!
qq info, qq go, qq kill, qq sync, qq wipe, qq respawn
You can operate on jobs submitted to another server. When you run any of these commands without an argument, the command operates on the job submitted from the current directory — in this case, even if the job is associated with a different batch server, all operations will work normally. In other words, you can get information about the job, navigate to its working directory, kill it, fetch files from the working directory, or delete the working directory, just as you would for a job submitted to your default batch server.
If you run any of these commands with an explicit job ID, and the job is on a different batch server than the default one, you need to provide the full job ID including the server address. Here is an example.
Suppose you are working on a Robox desktop, so your default batch server is robox-pro.ceitec.muni.cz. You have a job with ID 463242 running on this server. Running qq info 463242 works as expected — qq automatically expands the numerical ID to its full form 463242.robox-pro.ceitec.muni.cz.
Now suppose you want to get information about job 326432, which is running on the Sokar cluster. Running qq info 326432 would look up 326432.robox-pro.ceitec.muni.cz — which is not what you want, and will either produce an error or, worse, silently return information about the wrong job. To get information about the correct job, you need to provide the full job ID: 326432.sokar-pbs.ncbr.muni.cz.
qq cd
Similarly to the previous commands, you can run qq cd <full-job-id> to navigate to the input directory of a job submitted to a different server. As above, you need to provide the full job ID including the server address. Note that the input directory must be accessible under the same path on both the target server and your current machine.
qq killall
You can kill all your qq jobs on a specific server by running:
qq killall --server <server-name>
Warning
The
--serveroption is ignored on Karolina and LUMI, where only one batch server is available. You also cannot submit jobs from any of the Metacentrum-family clusters to Karolina and LUMI or vice versa.
Specifying resubmission hosts
When running a continuous or a loop job, each new cycle of the job is, by default, resubmitted either from the working node (where the job was running) or from the input machine (where the job was submitted from), depending on the batch system used. Currently, on Metacentrum-family clusters, the resubmission occurs from the input machine, while on Karolina and LUMI, the resubmission occurs from the working node.
This default behavior can be overridden by using the --resubmit-from option of qq submit:
qq submit -q default --ncpus 8 --job-type continuous --resubmit-from st1 job.sh
With this setting, all new cycles of the continuous job will be resubmitted from the st1 node, regardless of where they were originally submitted from. Note that qq does NOT need to be installed on the resubmission host, so you can use almost any computer with access to the batch server.
Resubmission hosts
To specify a resubmission host, you can either use its hostname or one of two special values: input or working.
If you specify the hostname directly, qq will connect to that host and resubmit the job from there. If you specify input, qq will connect to the input (submission) machine and resubmit the job from there. If you specify working, qq will not connect anywhere and will instead resubmit the job directly from the main working node on which the job is running.
Specifying multiple resubmission hosts
You can specify multiple resubmission hosts by separating them with commas, colons, or spaces. qq will primarily attempt to resubmit the job from the first host in the list and will fall back to the next host if the first one is unavailable. Note that each connection is attempted multiple times with a delay between attempts to accommodate transient network issues.
qq submit (...) --resubmit-from input,st1,working
With this setting, qq will first attempt to resubmit the job from the input node. If that is unavailable, it will fall back to st1, and if that is also unavailable, it will fall back to working.
Specifying resubmission hosts in a config file
You can globally configure the resubmission hosts in your qq configuration file:
[resubmitter]
default_resubmit_hosts = "input,st1,working"
Note
You only need to make this configuration file available on the original input machine from which the job is submitted. The settings will be transferred to the compute nodes and to the eventual resubmission host.
Miscellaneous
This section explains topics that did not fit elsewhere – what states a job can be in, what files qq creates, what environment variables are available inside your scripts, and how to configure qq’s behavior.
Job states
There are three types of job states that qq uses: batch states, naïve states, and real states.
- Batch states describe the job’s state according to the batch system itself.
- Naïve states are recorded in qq info files.
- Real states combine both sources of information to report the most accurate job status.
Batch states are shown in the output of qq jobs and qq stat, while real states are used by all other commands that report a job’s status.
Below are the meanings of the most common real states you may encounter:
- queued – The job has been submitted and is waiting in the queue for execution.
- held – The job has been submitted but is blocked from execution for some reason (typically due to an unsatisfied dependency).
- booting – The job has been allocated computing nodes and the working directory is being prepared, but it is not yet ready.
- running – The job is currently running; its script is being executed or the execution is being finalized.
- exiting –
qq runhas finished executing or is submitting the next job cycle (for loop jobs), but the batch system hasn’t completed the job yet. - finished – The job completed successfully (exit code 0) and data from the working directory were transferred to the input directory (if the default transfer mode was used).
- failed – The job’s execution failed (exit code > 0).
- killed – The job was terminated by the user, an administrator, or the batch system.
- in an inconsistent state – qq believes the job to be in a specific state which is incompatible with what the batch system reports. This usually indicates either a bug or that the job was manipulated outside qq.
- unknown – The job is in a state that qq does not recognize.
Runtime files
qq uses four types of runtime files, each with one of the following extensions: .qqinfo, .out, .err, and .qqout.
qqinfo files
A .qqinfo file (also called a “qq info file”) is created after submission by qq submit. It stores information used to track the job submitted from that directory. Each qq job requires its own info file for management and control.
Caution
Do NOT move, modify, or delete qq info files manually.
Always use qq commands such as
qq killorqq clearto manage them safely.
Moving, editing, or removing a qq info file while a job is running will cause the job to crash, and you may lose its data.
out files
A .out file contains the standard output from the script executed as a qq job. This file is created when the job starts running in the working directory and is copied to the input directory once the job is completed.
err files
A .err file contains the standard error output from the script executed as a qq job. Like the .out file, it is created when the job starts running in the working directory and is copied to the input directory once the job is completed.
qqout files
A .qqout file contains the output from the qq run execution environment. It includes technical information about the job’s progress and internal qq operations. If your batch system is PBS, this file is only placed into the input directory after the job is completed. If your batch system is Slurm, this file is available after the job starts running.
Environment variables
When a qq job is submitted, several environment variables are automatically set and can be used within the submitted script.
QQ_ENV_SET: indicates that the job is running inside the qq environment (always set totrue)QQ_INPUT_MACHINE: name of the input machine from which the job was submittedQQ_INPUT_DIR: absolute path to the job’s input directory on the input machineQQ_INFO: absolute path to the qq job’s info file on the input machineQQ_BATCH_SYSTEM: name of the batch system used to schedule and execute the jobQQ_NNODES: the total number of allocated compute nodesQQ_NCPUS: the total number of allocated CPU coresQQ_NGPUS: the total number of allocated GPU coresQQ_WALLTIME: the walltime of the job in hours
If the QQ_DEBUG environment variable is set when running qq submit, its value is propagated to the job environment as well. This turns on the debug mode, dramatically increasing the verbosity of qq run.
If the job is a loop job or a continuous job, the following environment variable is also set:
QQ_NO_RESUBMIT: exit code that can be returned from the body of the script to indicate that the next cycle of the job should not be submitted
If the job is a loop job, the following additional environment variables are also set:
QQ_LOOP_CURRENT: current cycle number of the loop jobQQ_LOOP_START: first cycle of the loop jobQQ_LOOP_END: last cycle of the loop jobQQ_ARCHIVE_FORMAT: filename format used for archived files
Important
Apart from the variables listed here and those provided by the batch system itself, no other environment variables can be guaranteed to be propagated from the submission environment to the job environment.
Additional internal environment variables may be set, but these are not intended for public use and may change or be removed in future versions of qq.
Configuration
qq is highly configurable. All user-adjustable options (colors, panel widths, timeouts, suffixes, environment variables, and batch-system behavior) are controlled through a single TOML configuration file.
qq automatically loads configuration from:
$QQ_CONFIGenvironment variable (highest priority)qq_config.toml(in the current directory)${HOME}/.config/qq/config.toml(default location, XDG-compatible)
If no file is found, qq falls back to built-in defaults.
Important
If you want the configuration to apply across the entire cluster, you must install it both on your desktop and in the home directories of all compute nodes. However, if you are only customizing qq’s appearance (see Themes), placing the configuration file on your desktop will probably suffice.
Configuration structure
The configuration file is a TOML document whose top-level tables correspond directly to qq’s internal configuration groups. You do not need to use all fields—omitted fields simply fall back to defaults.
An example of a tiny config file:
[state_colors]
running = "bright_green"
queued = "bright_yellow"
This configuration makes running jobs display in green (instead of the default blue) and queued jobs display in yellow (instead of the default purple). No other behavior is changed.
See all configurable options below.
Themes
Does writing your own configuration seem to complex? qq provides few ready-to-use themes, available from github.com/VachaLab/qq/tree/main/themes.
Available themes include:
- light_terminal — By default, qq assumes a dark terminal background. On light backgrounds, the default output may look very ugly. If you use a light terminal background, you should install this qq theme.
- traffic_lights_theme — Adjusts the colors used for job states: running jobs are green (instead of blue), queued jobs are yellow (instead of purple), failed jobs are red (default color), and finished jobs are blue (instead of green).
You may import these themes directly or copy pieces into your own configuration.
All configurable options
The following expanded TOML structure lists all available sections and fields. You can copy this into your config and modify only the pieces you care about.
Caution
We generally only recommend modifying qq’s appearance (tables with
presenterin name or thestate_colorstable).Changing any of
suffixes,env_vars,date_formats,exit_codes,binary_nameis dangerous and may potentially break qq’s functionality.
##############################################
# File suffixes used by qq.
##############################################
[suffixes]
# Suffix for qq info files.
qq_info = ".qqinfo"
# Suffix for qq output files.
qq_out = ".qqout"
# Suffix for captured stdout.
stdout = ".out"
# Suffix for captured stderr.
stderr = ".err"
##############################################
# Environment variable names used by qq.
##############################################
[env_vars]
# Indicates job is running inside the qq environment.
guard = "QQ_ENV_SET"
# Enables qq debug mode.
debug_mode = "QQ_DEBUG"
# Path to the qq info file for the job.
info_file = "QQ_INFO"
# Machine from which the job was submitted.
input_machine = "QQ_INPUT_MACHINE"
# Submission directory path.
input_dir = "QQ_INPUT_DIR"
# Whether submission was from shared storage.
shared_submit = "QQ_SHARED_SUBMIT"
# Name of the batch system used.
batch_system = "QQ_BATCH_SYSTEM"
# Current loop-cycle index.
loop_current = "QQ_LOOP_CURRENT"
# Starting loop-cycle index.
loop_start = "QQ_LOOP_START"
# Final loop-cycle index.
loop_end = "QQ_LOOP_END"
# Non-resubmit flag returned by a job script.
no_resubmit = "QQ_NO_RESUBMIT"
# Archive filename pattern.
archive_format = "QQ_ARCHIVE_FORMAT"
# Scratch directory on Metacentrum clusters.
pbs_scratch_dir = "SCRATCHDIR"
# Slurm account used for the job.
slurm_job_account = "SLURM_JOB_ACCOUNT"
# Storage type for LUMI scratch.
lumi_scratch_type = "LUMI_SCRATCH_TYPE"
# Total CPUs used.
ncpus = "QQ_NCPUS"
# Total GPUs used.
ngpus = "QQ_NGPUS"
# Total nodes used.
nnodes = "QQ_NNODES"
# Walltime in hours.
walltime = "QQ_WALLTIME"
##############################################
# Timeout settings in seconds.
##############################################
[timeouts]
# Timeout for SSH in seconds.
ssh = 60
# Timeout for rsync in seconds.
rsync = 600
##############################################
# Settings for Runner (qq run) operations.
##############################################
[runner]
# Maximum number of attempts when retrying an operation.
retry_tries = 3
# Wait time (in seconds) between retry attempts.
retry_wait = 300
# Delay (in seconds) between sending SIGTERM and SIGKILL to a job script.
sigterm_to_sigkill = 5
# Interval (in seconds) between successive checks of the running script's state.
subprocess_checks_wait_time = 2
# Default intepreter used to run the submitted scripts in the qq environment.
default_interpreter = "bash"
##############################################
# Settings for Resubmitter operations.
##############################################
[runner]
# Maximum number of attempts when retrying an operation.
retry_tries = 3
# Wait time (in seconds) between retry attempts.
retry_wait = 300
# List of hosts from which job resubmission should be attempted.
# If empty, the batch system defaults are used.
default_resubmit_hosts = ""
##############################################
# Settings for Archiver operations.
##############################################
[archiver]
# Maximum number of attempts when retrying an operation.
retry_tries = 3
# Wait time (in seconds) between retry attempts.
retry_wait = 300
##############################################
# Settings for Goer (qq go) operations.
##############################################
[goer]
# Interval (in seconds) between successive checks of the job's state
# (when waiting for the job to start).
wait_time = 5
##############################################
# Settings for qq loop jobs.
##############################################
[loop_jobs]
# Pattern used for naming loop jobs.
pattern = "+%04d"
# Pattern used for names of archived files.
archive_format = "job%04d"
# Default name of the archive directory.
archive_dir = "storage"
##############################################
# Settings for Presenter (qq info).
##############################################
[presenter]
# Style used for the keys in job status/info panel.
key_style = "default bold"
# Style used for values in job status/info panel.
value_style = "white"
# Style used for notes in job status/info panel.
notes_style = "grey50"
[presenter.job_status_panel]
# Maximal width of the job status panel.
max_width = null
# Minimal width of the job status panel.
min_width = 60
# Style of the border lines.
border_style = "white"
# Style of the title.
title_style = "white bold"
[presenter.full_info_panel]
# Maximal width of the job info panel.
max_width = null
# Minimal width of the job info panel.
min_width = 80
# Style of the border lines.
border_style = "white"
# Style of the title.
title_style = "white bold"
# Style of the separators between individual sections of the panel.
rule_style = "white"
[presenter.brief_info]
# Color of the job ID in brief info.
job_id_color = "default"
# Color of the directory path in brief info.
dir_path_color = "cyan"
# Color of the loop info in brief info.
loop_info_color = "grey70"
##############################################
# Settings for JobsPresenter (qq jobs/stat).
##############################################
[jobs_presenter]
# Maximal width of the jobs panel.
max_width = null
# Minimal width of the jobs panel.
min_width = 80
# Maximum displayed length of a job name before truncation.
max_job_name_length = 20
# Maximum displayed length of working nodes before truncation.
max_nodes_length = 40
# Style used for border lines.
border_style = "white"
# Style used for the title.
title_style = "white bold"
# Style used for the subtitle (server name).
subtitle_style = "white bold"
# Style used for table headers.
headers_style = "default"
# Style used for table values.
main_style = "white"
# Style used for job statistics.
secondary_style = "grey70"
# Style used for extra notes.
extra_info_style = "grey50"
# Style used for strong warning messages.
strong_warning_style = "bright_red"
# Style used for mild warning messages.
mild_warning_style = "bright_yellow"
# List of columns to show in the output.
# If not set, the settings for the current batch system will be used.
columns_to_show = null
# Code used to signify "total jobs".
sum_jobs_code = "Σ"
##############################################
# Settings for QueuesPresenter (qq queues).
##############################################
[queues_presenter]
# Maximal width of the queues panel.
max_width = null
# Minimal width of the queues panel.
min_width = 80
# Style used for border lines.
border_style = "white"
# Style used for the title.
title_style = "white bold"
# Style used for the subtitle (server name).
subtitle_style = "white bold"
# Style used for table headers.
headers_style = "default"
# Style used for the mark if the queue is available.
available_mark_style = "bright_green"
# Style used for the mark if the queue is not available.
unavailable_mark_style = "bright_red"
# Style used for the mark if the queue is dangling.
dangling_mark_style = "bright_yellow"
# Style used for information about main queues.
main_text_style = "white"
# Style used for information about reroutings.
rerouted_text_style = "grey50"
# Code used to signify "other jobs".
other_jobs_code = "O"
# Code used to signify "total jobs".
sum_jobs_code = "Σ"
##############################################
# Settings for NodesPresenter (qq nodes).
##############################################
[nodes_presenter]
# Maximal width of the nodes panel.
max_width = null
# Minimal width of the nodes panel.
min_width = 80
# Maximal width of the shared properties section.
max_props_panel_width = 40
# Style used for border lines.
border_style = "white"
# Style used for the title.
title_style = "white bold"
# Style used for the subtitle (server name).
subtitle_style = "white bold"
# Style used for table headers.
headers_style = "default"
# Style of the separators between individual sections of the panel.
rule_style = "white"
# Name to use for the leftover nodes that were not assigned to any group.
others_group_name = "other"
# Name to use for the group if it contains all nodes.
all_nodes_group_name = "all nodes"
# Style used for main information about the nodes.
main_text_style = "white"
# Style used for statistics and shared properties.
secondary_text_style = "grey70"
# Style used for the mark and resources if the node is free.
free_node_style = "bright_green bold"
# Style used for the mark and resources if the node is partially free.
part_free_node_style = "green"
# Style used for the mark and resources if the node is busy.
busy_node_style = "blue"
# Style used for all information about unavailable nodes.
unavailable_node_style = "bright_red"
##############################################
# Date and time format strings.
##############################################
[date_formats]
# Standard date format used by qq.
standard = "%Y-%m-%d %H:%M:%S"
# Date format used by PBS Pro.
pbs = "%a %b %d %H:%M:%S %Y"
# Date format used by Slurm.
slurm = "%Y-%m-%dT%H:%M:%S"
##############################################
# Exit codes used for various errors.
##############################################
[exit_codes]
# Returned when a qq script is run outside the qq environment.
not_qq_env = 90
# Default error code for failures of qq commands or most errors in the qq environment.
default = 91
# Returned when a qq job fails and its error state cannot be written to the qq info file.
qq_run_fatal = 92
# Returned when a qq job fails due to a communication error between qq services.
qq_run_communication = 93
# Used by job scripts to signal that a loop job should not be resubmitted.
qq_run_no_resubmit = 95
# Returned on an unexpected or unhandled error.
unexpected_error = 99
##############################################
# Color scheme for states display.
##############################################
[state_colors]
# Style used for queued jobs.
queued = "bright_magenta"
# Style used for held jobs.
held = "bright_magenta"
# Style used for suspended jobs.
suspended = "bright_black"
# Style used for waiting jobs.
waiting = "bright_magenta"
# Style used for running jobs.
running = "bright_blue"
# Style used for booting jobs.
booting = "bright_cyan"
# Style used for killed jobs.
killed = "bright_red"
# Style used for failed jobs.
failed = "bright_red"
# Style used for finished jobs.
finished = "bright_green"
# Style used for exiting jobs.
exiting = "bright_yellow"
# Style used for jobs in an inconsistent state.
in_an_inconsistent_state = "grey70"
# Style used for jobs in an unknown state.
unknown = "grey70"
# Style used whenever a summary of jobs is provided.
sum = "white"
# Style used for "other" job states.
other = "grey70"
##############################################
# Options associated with the Size dataclass.
##############################################
[size]
# Maximal relative error acceptable when rounding Size values for display.
max_rounding_error = 0.1
##############################################
# Options associated with PBS.
##############################################
[pbs_options]
# Name of the subdirectory inside SCRATCHDIR used as the job's working directory.
scratch_dir_inner = "main"
##############################################
# Options associated with Slurm.
##############################################
[slurm_options]
# Maximal number of threads used to collect information about jobs using scontrol.
jobs_scontrol_nthreads = 8
##############################################
# Options associated with Slurm on IT4I clusters.
##############################################
[slurm_it4i_options]
# Number of attempts when preparing a working directory on scratch.
scratch_dir_attempts = 3
##############################################
# Options associated with Slurm on LUMI.
##############################################
[slurm_lumi_options]
# Number of attempts when preparing a working directory on scratch.
scratch_dir_attempts = 3
##############################################
# Options associated with transferring and archiving files.
##############################################
[transfer_files_options]
# Default transfer mode used for jobs.
default_transfer_mode = "success"
# Default archive mode used for jobs.
default_archive_mode = "success"
##############################################
# Options associated with working with non-default batch servers.
##############################################
[batch_servers_options]
# Dictionary mapping known server shortcuts to full server names.
[batch_servers_options.known_servers]
robox = "robox-pro.ceitec.muni.cz"
sokar = "sokar-pbs.ncbr.muni.cz"
metacentrum = "pbs-m1.metacentrum.cz"
meta = "pbs-m1.metacentrum.cz"
# Dictionary mapping known server names to frontends / output hosts.
[batch_servers_options.known_output_hosts]
"robox-pro.ceitec.muni.cz" = "st1.ceitec.muni.cz"
"sokar-pbs.ncbr.muni.cz" = "sokar.ncbr.muni.cz"
"pbs-m1.metacentrum.cz" = "perian.metacentrum.cz"
##############################################
# Options associated with multithreaded execution.
##############################################
[parallelization_options]
# Maximal number of threads used to collect job information.
job_info_max_threads = 16
# Maximal number of threads used to submit jobs in parallel.
submission_max_threads = 8
# Maximal number of threads used to clear runtime files in parallel.
clear_max_threads = 8
##############################################
# General configuration
##############################################
# Name of the qq binary.
binary_name = "qq"
Tools and API
This section covers ready-to-use run scripts for common simulation workflows, as well as the qq_lib Python library for integrating qq functionality directly into your own scripts and tools.
Gromacs run scripts
The qq GitHub repository provides several ready-to-use scripts for running Gromacs simulations in loops — similar to Infinity’s precycle scripts.
These scripts are compatible with all qq-supported clusters, including Metacentrum-family clusters, Karolina, and LUMI. You just have to remember to modify the script to load Gromacs from the module appropriate for the given cluster.
Important
For LUMI users: If you are using full nodes on the LUMI’s GPU queues, the run scripts may require some modifications to get solid performance (see here).
qq_loop_md
A job script for running single-directory Gromacs simulations in loops.
Start by preparing a directory containing all necessary input files, and place qq_loop_md inside it.
In your .mdp file, specify the number of simulation steps to perform in each cycle. In the body of the script, set the total number of cycles to run (using the qq loop-end directive), define input filenames, specify the Gromacs module to load, and optionally adjust the number of MPI ranks and OpenMP threads to use. By default, qq assigns one MPI rank per CPU core. If any GPUs are requested, one MPI rank per GPU is used and the remaining CPU cores are distributed among the MPI ranks as OpenMP threads.
Once ready, submit the job with qq submit. The first cycle will be submitted and executed, and before it finishes, qq will automatically submit the next cycle. Read more about qq loop jobs here.
The total simulation length after all cycles finish equals: (steps per cycle in the .mdp file) × (number of cycles).
qq_flex_md
A job script for running single-directory Gromacs simulations in flexible-length loops.
This script works similarly to qq_loop_md, but here the .mdp file specifies the total number of simulation steps to perform. Each cycle runs until it either exhausts its walltime or reaches the specified total number of steps. When a cycle ends, the script checks whether the target step count has been reached; if not, it automatically submits the next cycle. As a result, each cycle may have a different duration.
The total simulation length after all cycles finish corresponds to the number of steps specified in the .mdp file.
qq_loop_re
A job script for running multi-directory Gromacs simulations in loops. It functions like qq_loop_md, but instead of a single simulation, it manages multiple simulations across several subdirectories.
Place qq_loop_re in the parent directory containing your subdirectories. In the script body, specify the naming pattern for the subdirectories (e.g., win for win01, win02, …, win42, etc.).
This script is typically used for replica exchange simulations (hence the re in its name). You can thus also set the exchange attempt frequency and choose whether to perform Hamiltonian replica exchange. You can also use the script to run multiple-walker metadynamics or AWH.
Note that by default, qq_loop_re and qq_flex_re scripts use a single MPI rank per GPU (if requested) or per CPU core.
The total simulation length after all cycles finish equals: (steps per cycle in the .mdp file) × (number of cycles).
qq_flex_re
A job script for running multi-directory Gromacs simulations in flexible-length loops — essentially a hybrid of qq_loop_re and qq_flex_md.
Each cycle runs until it reaches the specified total number of steps or the walltime limit, automatically submitting the next cycle if needed.
The total simulation length after all cycles finish equals the number of steps specified in the .mdp file.
Prolonging the simulations
After your simulations finish, you may find that you want them to continue for a bit longer.
qq_loop_md / qq_loop_re
Prolonging simulations run with qq_loop_* scripts is straightforward. Increase the value in the # qq loop-end ... directive to extend the total number of cycles, then submit the loop script again using qq submit. You do not need to remove the runtime files in the directory. The loop job will resume from the next cycle.
qq_flex_md / qq_flex_re
Prolonging simulations run with qq_flex_* scripts is a bit more involved: you must extend the Gromacs tpr file (or files, in the case of qq_flex_re) to include more simulation time.
You can do this with:
gmx_mpi convert-tpr -s storage/md<NEXT_CYCLE_NUMBER>.tpr -until <TOTAL_SIMULATION_RUN> -o storage/md<NEXT_CYCLE_NUMBER>.tpr
<NEXT_CYCLE_NUMBER> is the number of the next cycle of the loop job. <TOTAL_SIMULATION_RUN> is the new total simulation time in picoseconds. See the documentation of gmx convert-tpr for more details.
If you are using qq_flex_re, you must update tpr files for all clients created for the next cycle in the storage directory. Their names follow this format:
md<NEXT_CYCLE_NUMBER>-<DIRECTORY_IDENTIFIER>.tpr
Once the tpr files are updated, simply submit the flex script again using qq submit. You do not need to remove the runtime files in the directory.
Using qq in Python
Tip
Looking for how to run Python scripts as qq jobs instead? See this section of the manual.
qq is built on top of qq_lib, a Python library that exposes core qq functionality programmatically. You can install qq_lib to integrate qq workflows directly into your Python scripts.
The recommended way to use qq_lib is to use the uv package manager.
To add qq_lib to your project:
uv add git+https://github.com/VachaLab/qq.git --tag v0.12.0
Alternatively, you can add it directly to a specific script:
uv add git+https://github.com/VachaLab/qq.git --tag v0.12.0 --script [YOUR_SCRIPT].py
Then import qq classes and utilities in your Python code:
from qq_lib.info import Informer
from qq_lib.kill import Killer
And use them:
informer = Informer.from_file("my_job.qqinfo")
print(informer.get_real_state())
killer = Killer.from_informer(informer)
killer.kill()
See the Python API documentation for details on available modules, classes, and functions.
Official qq scripts
qq offers several official helper scripts built on top of qq_lib. These tools automate common workflows—especially useful when running many Gromacs simulations—but are not part of core qq functionality. You can find them in the qq GitHub repository.
Again, the recommended approach is to use the uv package manager. If you have uv installed, download the script, make it executable (chmod u+x SCRIPT), and run it (./SCRIPT). If you use the scripts frequently, consider adding their directory to your PATH.
gmx-eta
gmx-eta estimates the remaining runtime of a Gromacs simulation. Run it in a directory containing a qq job, supply job ID(s), or use the --all flag.
Important
gmx-etarequires that your Gromacsmdruncommand is executed with the-vflag.
Usage
usage: gmx-eta [-h] [--all] [job_id ...]
Get the estimated time of a Gromacs simulation finishing.
positional arguments:
job_id Job ID(s). Optional. If not provided, ETA is obtained for the newest job submitted from the current directory.
options:
-h, --help show this help message and exit
--all, -a Show ETA for all jobs.
Examples
Using a single job ID:
$ gmx-eta 12345
[12345] gromacs_job: Simulation will finish in 06:41:07.
Using multiple job IDs:
$ gmx-eta 12345 12356
[12345] gromacs_job: Simulation will finish in 06:41:07.
[12356] gromacs_job: Simulation will finish in 05:23:57.
Using the --all flag:
$ gmx-eta --all
[12345] gromacs_job: Simulation will finish in 06:41:07.
[12356] gromacs_job: Simulation will finish in 05:23:57.
[12444] gromacs_job_new: Simulation will finish in 08:45:12.
[12458] gromacs_job_new: Simulation will finish in 11:33:01.
Without arguments inside an input directory of a job:
$ gmx-eta
[12444] gromacs_job_new: Simulation will finish in 08:45:12.
Warning
The following scripts are deprecated. You can still use them, but their functionality is now part of core qq. See job collections for more information.
multi-check
multi-check scans multiple directories for qq jobs and reports their collective status. It uses multithreading to significantly speed up job-state inspection compared to checking jobs individually.
Usage
usage: multi-check [-h] [-t THREADS] [--fix] directories [directories ...]
Check the state of qq jobs in multiple directories.
positional arguments:
directories Directories containing qq info files.
options:
-h, --help show this help message and exit
-t, --threads THREADS Number of worker threads (default: 16)
--fix Resubmit all failed and killed jobs.
Example check
$ multi-check win??
Collecting job states ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
FAILED 4
win05 win06 win07 win08
FINISHED 3
win45 win48 win49
QUEUED 35
win01 win02 win03 win04 win09 win10 win11 win12 win13 win14 win15 win16 win17 win18 win20 win21 win22 win23 win24 win25 win26 win27 win28 win29 win30 win31 win32 win33 win34 win35 win36 win38 win39 win42 win43
RUNNING 9
win19 win37 win40 win41 win44 win46 win47 win50 win51
TOTAL 51
You may also use --fix to automatically attempt to respawn jobs in FAILED or KILLED states. Jobs are respawned with the same parameters originally used.
Example fix
$ multi-check win?? --fix
Collecting job states ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
FAILED 4
win05 win06 win07 win08
FINISHED 3
win45 win48 win49
QUEUED 35
win01 win02 win03 win04 win09 win10 win11 win12 win13 win14 win15 win16 win17 win18 win20 win21 win22 win23 win24 win25 win26 win27 win28 win29 win30 win31 win32 win33 win34 win35 win36 win38 win39 win42 win43
RUNNING 9
win19 win37 win40 win41 win44 win46 win47 win50 win51
TOTAL 51
***********************************
Fixing jobs ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
FIXED SUCCESSFULLY 4
win05 win06 win07 win08
COULD NOT FIX 0
multi-submit
multi-submit submits qq jobs from multiple directories in bulk. All jobs must use the same submission script name and request identical resources. The resource specification from the first submitted job is applied to all others. It uses multithreading to significantly speed up job submission compared to submitting jobs individually.
Usage
usage: multi-submit [-h] script directories [directories ...]
Submit qq jobs from multiple directories. All jobs must request the same resources!
positional arguments:
script Name of the script to submit.
directories Directories containing qq info files.
options:
-t, --threads THREADS Number of worker threads (default: 16)
-h, --help show this help message and exit
Example
$ multi-submit qq_loop_md win?? -q default --ncpus=8 --walltime=12h
Submitting jobs ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
SUBMITTED SUCCESSFULLY 51
win01 win02 win03 win04 win05 win06 win07 win08 win09 win10 win11 win12 win13 win14 win15 win16 win17 win18 win19 win20 win21 win22 win23 win24 win25 win26 win27 win28 win29 win30 win31 win32 win33 win34 win35 win36 win37 win38 win39 win40 win41 win42 win43 win44 win45 win46 win47 win48 win49 win50 win51
COULD NOT SUBMIT 0
multi-kill
multi-kill terminates qq jobs across multiple directories in parallel. Because it uses multithreading, it is significantly faster than running qq kill for each job independently.
Usage
usage: multi-kill [-h] [-t THREADS] directories [directories ...]
Kill qq jobs in multiple directories.
positional arguments:
directories Directories containing qq info files.
options:
-h, --help show this help message and exit
-t, --threads THREADS
Number of worker threads (default: 16)
Example
$ multi-kill win??
Killing jobs ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
KILLED SUCCESSFULLY 51
win01 win02 win03 win04 win05 win06 win07 win08 win09 win10 win11 win12 win13 win14 win15 win16 win17 win18 win19 win20 win21 win22 win23 win24 win25 win26 win27 win28 win29 win30 win31 win32 win33 win34 win35 win36 win37 win38 win39 win40 win41 win42 win43 win44 win45 win46 win47 win48 win49 win50 win51
COULD NOT KILL 0
Glossary
-
compute node – Computer where a job can be executed.
-
continuous job – Simple alternative to a loop job. Job which submits its continuation right before finishing, while not performing any other advanced operations [read more].
-
input directory – Directory from which the job is submitted. Contains the qq info file.
-
job directory – See “input directory”.
-
loop job – Job which submits its continuation right before finishing, archives files and counts cycles [read more].
-
main working node – Working node (see below) responsible for managing a job.
-
qq info file – YAML-formatted file containing information about a qq job. Necessary for performing operations with the qq job. Located in the input directory.
-
qq job – Job of the batch system submitted using
qq submit. -
standard job – Default qq job [read more].
-
submission directory – See “input directory”.
-
work(ing) directory – Directory where the job is being executed [read more].
-
working node – Compute node where the job is being (or has been) executed.
Common issues
Tip
If something does not work or behaves unexpectedly, it’s never your fault — it’s either a bug or an unclear documentation. Report it!
Here are some issues that you may encounter when installing or using qq.
Submitted jobs fail on a node
You submit a job, it starts being executed, and then it finishes way too quickly. qq info says that the job is in an inconsistent state, and your .qqout file contains the following output:
/usr/bin/env: 'qq': No such file or directory
This indicates that qq is not available on the computing node where the job was executed. Any of the following things might have gone wrong:
qqhas not been installed on the concerned computing node at all.
This may be especially common on the Robox cluster if you run the job on someone else’s desktop. When installing qq on Robox, it is installed only on your desktop and on the computing nodes, not on other people’s desktops. This is a feature, not a bug — you probably should not run jobs on other people’s desktops. If you need to, you can rerun the installation command on their desktop.
qqhas been installed, but the RC file (.bashrc, typically) has not been properly modified.
Connect to the node where your job was executed and check the contents of ${HOME}/.bashrc.
The file should contain a block similar to this:
# >>> This block is managed by qq >>>
# This makes qq available for you on any computer using this directory as its HOME.
if [[ ":$PATH:" != *":/home/ladme/qq:"* ]]; then
export PATH="$PATH:/home/ladme/qq"
fi
# This makes the qq cd command work.
qq() {
if [[ "$1" == "cd" ]]; then
for arg in "$@"; do
if [[ "$arg" == "--help" || "$arg" == "-h" ]]; then
command qq "$@"
return
fi
done
target_dir="$(command qq cd "${@:2}")"
cd "$target_dir" || return
else
command qq "$@"
fi
}
# This makes qq autocomplete work.
eval "$(_QQ_COMPLETE=bash_source qq)"
# <<< This block is managed by qq <<<
If this block is not in the .bashrc file, first try reinstalling qq on the cluster. If that does not help, open a GitHub issue.
qqhas been installed,.bashrchas been modified, but it is not read before executing the job.
This may indicate that when a job was run on the affected node, a login shell was opened instead of the typically used non-login shell. In such cases, the .bashrc file may not be read; instead, either the .profile or .bash_profile file will be read. We need to force the shell to read the .bashrc file. Connect to the affected computing node, go to your HOME directory (cd ~), and add the following to both .profile and .bash_profile located there:
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
Note
If
.profileand.bash_profiledo not exist,
PBS GSS error - No credentials were supplied
On Robox, Sokar, or Metacentrum clusters, you may get the following error when running qq jobs, qq stat, qq nodes, or qq queues:
ERROR Could not retrieve information about jobs: pbs_gss_establish_context: GSS - gss_acquire_cred: No credentials were supplied, or the credentials were unavailable or inaccessible.
pbs_gss_establish_context: GSS - gss_acquire_cred: unknown mech-code 0 for mech unknown
auth: error returned: 15010
auth: auth_process_handshake_data failure
Permission denied
This indicates that your Kerberos ticket has expired. Run kinit and provide your password when prompted to generate a new Kerberos ticket. Then rerun the qq command.
sbatch error: AssocMaxSubmitJobLimit
On Karolina and LUMI, you may get the following error when submitting a job:
ERROR Failed to submit script '<script_name>': sbatch: error: AssocMaxSubmitJobLimit
sbatch: error: Batch job submission failed: Job violates accounting/QOS policy (job submit limit, user's size and/or time limits).
This usually indicates that you did not provide the required --account option. Provide it along with your project ID (something like OPEN-AB-CD on Karolina or project_123456 on LUMI; check the output of it4ifree or lumi-allocations, respectively).
In case you did provide the --account option, you are probably running too many jobs on a given queue, you have used all the resources allocated for your project, the specified walltime for your job is too long, or you are asking for too many resources.
I have some other issue
Open a GitHub issue or write an e-mail to ladmeb@gmail.com.